How does Google understand text?

At Yoast, we talk a lot about writing and readability. We consider it an essential part of SEO. Your text needs to be easy to follow and it needs to satisfy your users’ needs. This focus on your user will help your rankings. However, we rarely talk about how search engines like Google read and understand these texts. In this post, we’ll explore what we know about how Google analyzes your online content.
Are we sure Google understands text?
We know that Google understands text to some degree. Just think about it. One of the most important things Google has to do is match what someone types into the search bar to a suitable search result. User signals (like click-through and bounce rates) alone won’t help Google to do this properly. Moreover, we know that it’s possible to rank for a keyword that you don’t use in your text (although it’s still good practice to identify and use one or more specific keywords). So clearly, Google does something to actually read and assess your text in some way or another.
How Google understands text
Back to our initial question: How does Google understand text? To be honest, we don’t know this in detail. Unfortunately, that information isn’t freely available. And we also know, that Google is continuously evolving their ability to understand text online. But there are some clues that we can draw conclusions from. We know that Google has taken big steps when it comes to understanding context. We also know that the search engine tries to determine how words and concepts are related to each other. How do we know this? By keeping an eye on any news surrounding Google’s algorithm and considering how the actual search results pages have changed.
Word embeddings
One interesting technique Google has filed patents for and worked on is called word embedding. The goal is to find out what words are closely related to other words. A computer program is fed a certain amount of text. It then analyzes the words in that text and determines what words tend to appear together. Then, it translates every word into a series of numbers. This allows the words to be represented as a point in space in a diagram, like a scatter plot. This diagram shows what words are related in what ways. More accurately, it shows the distance between words, sort of like a galaxy made up of words. So for example, a word like “keywords” would be much closer to “copywriting” than it would be to say “kitchen utensils”.
Interestingly, this can also be done for phrases, sentences and paragraphs. The bigger the dataset you feed the program, the better it will be able to categorize and understand words and work out how they’re used and what they mean. And, what do you know, Google has a database of the entire internet. With a dataset like that, it’s possible to create very reliable models that predict and assess the value of text and context.
Related entities
From word embeddings, it’s only a small step to the concept of related entities. Let’s take a look at the search results to illustrate what related entities are. If you type in “types of pasta”, this is what you’ll see right at the top of the SERP: a heading called “pasta varieties”, with a number of rich results that include a ton of different types of pasta. These pasta varieties are even subcategorized into “ribbon pasta”, “tubular pasta”, and other subtypes of pasta. And there are lots of similar SERPs that reflect how words and concepts are related to each other.
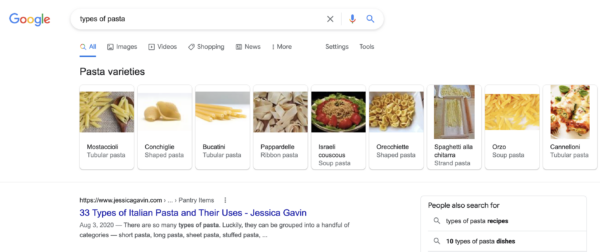
The related entities patent that Google has filed actually mentions the related entities index database. This is a database that stores concepts or entities, like pasta. These entities also have characteristics. Lasagna, for example, is a pasta. It’s also made of dough. And it’s food. Now, by analyzing the characteristics of entities, they can be grouped and categorized in all kinds of different ways. This allows Google to understand how words are related, and, therefore, to understand context.
Google has heavily invested in NLP
Natural language processing is the understanding of language by machines. It is one of the hardest parts of computer science and one where the most advances are being made. Today, with a world increasingly powered by systems run by AI, proper language understanding is key. Google understands this and invests a ton in the development of NLP models. One key system was BERT, a model that could understand the text coming after the content words and before those words. This way, the system has the full context of a sentence to make proper sense of its meaning. What BERT did is awesome, but Google is doing more. Meet MUM.
MUM: Google’s language model
In 2021, Google introduced a new language model that can multitask: MUM. This means that this model can read text, understand its meaning, form a deeper knowledge about the subject, use other media to enrich that knowledge, get insights from more than 75 languages and translate everything into content that answers complex search queries. All at the same time.
Does the rise of AI change all of this?
Over the past year, we’ve seen a lot of developments in the area of AI. Naturally, Google could not stay behind and introduced their own set of tools including the well-known AI model Gemini. Most recently, they introduced AI overviews in their search engine. And you might have already guessed it, but natural language processing models come in handy when you’re developing AI features. So Google’s ongoing research into NLP and machine learning is not slowing down anytime soon.
Practical conclusions
So, how does Google understand text exactly? What we know leads us to two very important points:
1. Context is key
If Google understands context, it’s likely to assess and judge context as well. The better your copy matches Google’s notion of the context, the better its chances of ranking well. So thin copy with a limited scope is going to be at a disadvantage. You need to cover your topics properly and in enough detail. And on a larger scale, covering related concepts and presenting a full body of work on your site will reinforce your authority on the topic you write about and specialize in.
2. Write for your reader
Texts that are easy to read and reflect relationships between concepts don’t just benefit your readers, they help Google as well. Difficult, inconsistent and poorly structured writing is more difficult to understand for both humans and machines. You can help the search engine understand your texts by focusing on:
- Readability: making your text as easy to read as possible without compromising your message.
- Proper structure: adding clear subheadings and using transition words.
- Good content: adding clear explanations that show how what you’re saying relates to what’s already known about a topic.
The better you do, the easier your users and Google will understand your text and what it tries to achieve. Which also helps you rank with the right pages when a user types in a certain search query. Especially because Google is basically creating a model that mimics the way humans process language and information.
Google wants to be a reader
In the end, it boils down to this: Google is becoming more and more like an actual reader. By writing rich content that is well-structured and easy to read and embedded into the context of the topic at hand, you’ll improve your chances of doing well in the search results.
Read more: SEO copywriting: the ultimate guide »
