Crawl efficiency: making Google’s crawl easier

Search engines crawl your site to get the contents into their index. The bigger your site gets, the longer this crawl takes. It’s important that the time spent crawling your site is well spent. If your site has 1,000 pages or less, this is not a topic you’ll need to think about much. If you intend on growing your site though, keep on reading. Acquiring some good habits early on can save you from huge headaches later on. In this article, we’ll cover what crawl efficiency is and what you can do about it.
All search engines crawl the same way. In this article, we’ll refer to Google and Googlebot.
How does a crawl of your site work?
Google finds a link to your site somewhere on the web. At that point, that URL is the beginning of a virtual pile. The process is pretty easy after that:
- Googlebot takes one page from that pile;
- it crawls the page and indexes all the contents for use in Google;
- it then adds all the links on that page to the pile.
During the crawl, Googlebot might encounter a redirect. The URL it’s redirected to goes on the pile.
Your primary goal is to make sure Googlebot can get to all pages on the site. A secondary goal is to make sure new and updated content gets crawled fast. Good site architecture will help you reach that goal. It is imperative though that you maintain your site well.
Crawl depth
An important concept while talking about crawling is the concept of crawl depth. Say you had 1 link, from 1 site to 1 page on your site. This page linked to another, to another, to another, etc. Googlebot will keep crawling for a while. At some point though, it’ll decide it’s no longer necessary to keep crawling. When that point is, depends on how important the link pointing at that first page is.
This might seem theoretical, so let’s look at a practical example. If you have 10,000 posts, all in the same category and you show 10 articles per page. These pages only link to “Next »” and “« Previous”. Google would need to crawl 1,000 pages deep to get to the first of those 10,000 posts. On most sites, it won’t do that.
This is why it’s important to:
- Use categories / tags and other taxonomies for more granular segmentation. Don’t go overboard on them either. As a rule of thumb, a tag is only useful when it connects more than 3 pieces of content. Also, make sure to optimize those category archives.
- Link to deeper pages with numbers, so Googlebot can get there quicker. Say you link page 1 to 10 on page 1 and keep doing that. In the example above, the deepest page would only be 100 clicks away from the homepage.
- Keep your site fast. The slower your site, the longer a crawl will take.
XML Sitemaps and crawl efficiency
Your site should have one or more XML sitemaps. Those XML sitemaps tell Google which URLs exist on your site. A good XML sitemap also indicates when you’ve last updated a particular URL. Most search engines will crawl URLs in your XML sitemap more often than others.
In Google Search Console, XML sitemaps give you an added benefit. For every sitemap, Google will show you errors and warnings. You can use this by making different XML sitemaps for different types of URLs. This means you can see what types of URLs on your site have the most issues.
Read more: How to add your website to Google Search Console »
Problems that cause bad crawl efficiency
Many 404s and other errors
While it crawls your site, Google will encounter errors. It’ll usually just pick the next page from the pile when it does. If you have a lot of errors on your site during a crawl, Googlebot will slow down. It does that because it’s afraid that it’s causing the errors by crawling too fast. To prevent Googlebot from slowing down, you thus want to fix as much errors as you can.
Google reports all those errors to you in its Webmaster Tools, as do Bing and Yandex. We’ve covered errors in Google Search Console (GSC) and Bing Webmaster Tools before. The Redirect manager in Yoast SEO Premium helps you fix these errors by redirecting these to correct URLs.
You wouldn’t be the first client we see that has 3,000 actual URLs and 20,000 errors in GSC. Don’t let your site become that site. Fix those errors on a regular basis, at least every month.
Excessive 301 redirects
I was recently consulting on a site that had just done a domain migration. The site is big, so I used one of our tools to run a full crawl of the site and see what we should fix. It became clear we had one big issue. A large group of URLs on this site is always linked to without a trailing slash. If you go to such a URL without the trailing slash, you’re 301 redirected. You’re redirected to the version with the trailing slash.
If that’s an issue for one or two URLs on your site it doesn’t really matter. It’s actually often an issue with homepages. If that’s an issue with 250,000 URLs on your site, it becomes a bigger issue. Googlebot doesn’t have to crawl 250,000 URLs but 500,000. That’s not exactly efficient.
This is why you should always try to update links within your site when you change URLs. If you don’t, you’ll get more and more 301 redirects over time. This will slow down your crawl and your users. Most systems take up to a second to server a redirect. That adds another second onto your page load time.
Spider traps
If your site is somewhat more authoritative in Google’s eyes, fun things can happen. Even when it’s clear that a link doesn’t make sense, Google will crawl it. Give Google the virtual equivalent of an infinite spiral staircase, it’ll keep going. I want to share a hilarious example of this I encountered at the Guardian.
At the Guardian we used to have daily archives for all our main categories. As the Guardian publishes a lot of content, those daily archives make sense. You could click back from today, to yesterday and so on. And on. And on. Even to long before the Guardian’s existence. You could get to December 25th of the year 0 if you were so inclined. We’ve seen Google index back to the year 1,600. That’s almost 150,000 clicks deep.
This is what we call a “spider trap“. Traps like these can make a search engines crawl extremely inefficient. Fixing them almost always leads to better results in organic search. The bigger your site gets, the harder issues like these are to find. This is true even for experienced SEOs.
Tools to find issues and improve crawl efficiency
If you’re intrigued by this and want to test your own site, you’re going to need some tools. We used Screaming Frog a lot during our site reviews. It’s the Swiss army knife of most SEOs. Some other SEOs I know swear by Xenu, which is also pretty good (and free). Be aware: these are not “simple” tools. They are power tools that can even take down a site when used wrong, so take care.
A good first step is to start crawling a site and filter for HTML pages. Then sort descending by HTTP status code. You’ll see 500 – 400 – 300 type responses on the top of the list. You’ll be able to see how bad your site is doing, compared to the total number of URLs. See an example below:
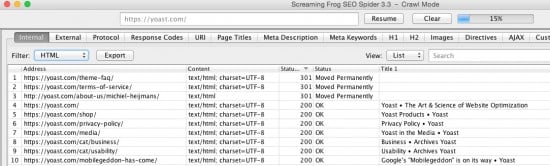
How’s your sites crawl efficiency?
I’d love to hear if you’ve had particular issues like these with crawl efficiency and how you solved them. Even better if this post helped you fix something, come tell us below!
Assess your technical SEO fitness
Crawl efficiency is an essential part of technical SEO. Curious how fit your site’s overall technical SEO is? We’ve created a technical SEO fitness quiz that helps you figure out what you need to work on!
Keep reading: robots.txt: the ultimate guide »

Thanks for the article, I have a question.
Is it going to be a big problem for the crawlers if I delete my tags from the blog? They are “noidexed”, but still Screaming Frog is showing their pages as duplicate content + I see my competitors and 80$+ of them doesn’t have tags.
Colleagues of mine said – “If you have noindex, ignore it and don’t do anything.”
P.S. /Settings>Advanced>Respect noindex/ is kept in mind…
Thanks, for sharing such an informative post. I have started using ScreamingFrog after reading this post.
Hey This was really a helpful article.
Keep up the Good work!?
My tags are not ranking, what could be the issue?
Hi Manqonqo, First make sure you’ve haven’t noindexed them by accident. Then check if you have optimized your tag pages. Did you add some valuable content to your tag pages? Otherwise you might have other more content rich articles that rank for your tag pages’ terms. Which is not a problem per se!
Hi, Joost!
Thanks for this awesome article. Nowadays crawling one of the most important questions in SEO. Using Screaming From more than 3 years, think it’s the best tool for webmasters.