How to use Google Search Console: a beginner’s guide

Do you have a website or maintain the website of the company you work for? Of course, to do this right, you need to keep a keen eye on the performance of your website. Google offers several tools to collect and analyze data from your website. You probably have heard of Google Analytics and Google Search Console before. These tools are free for everyone maintaining a website and can give you valuable insights about your website. Here, we’ll explain how to use Google Search Console for SEO!
Why use Google Search Console?
Google Search Console helps you track the performance of your website easily. You can get valuable insights from your Google Search Console account, which means you can see what part of your website needs work. This can be a technical part of your website, such as an increasing number of crawl errors that need to be fixed. This can also give a specific keyword more attention because the rankings or impressions are decreasing. Or find the reasons why some pages aren’t indexed.
Besides seeing this kind of data, you’ll get email notifications when Google Search Console notices new errors. Because of these notifications, you’re quickly aware of issues you must fix. That’s why everyone with a website should learn how to use it!
Search Console is structured around various sections
Search Console has several sections, which keep expanding as Google adds more:
- URL Inspection
- The URL Inspection tool lets you get insights on specific URLs and how Google sees and indexes them. You’ll also see if the page is eligible for rich results.
- Performance
- In the Performance section, you’ll discover how your site is doing in the regular search results, on Discover, and Google News, if it is eligible for those.
- Indexing
- In the Indexing section, you’ll find all the insights you need to see how Google discovers and indexes your pages. You can also learn if and how Google is indexing the video content on your site. There’s also a section to check your XML sitemaps and any page removals you may have requested.
- Experience
- The Experience section gives you an idea of how Google values your page’s performance on mobile and desktop, with a little help from Core Web Vitals, and whether your pages are served via HTTPS connections.
- Shopping
- In the Shopping tab, you’ll find more information about how Google sees your products — if you own an ecommerce site or sell something else online. You can see which products have rich results, plus insights into your merchant listings and how you appear in Google Shopping.
- Enhancements
- The Enhancements section lists all the structured data that Google found on your site and whether or not it is eligible for rich results. This includes events, reviews, job postings, and more.
- Security & Manual Actions
- The Security & Manual Actions destination shouldn’t be visited often, as it lists security issues found by Google or when it issues a manual action against your site.
- Links
- The Links section overviews your site’s internal and external links.
Setting up an account
You’ll need to create an account to start using Google Search Console. Within Google Search Console, you can click on ‘add a new property’ in the top bar:
You can insert the website you want to add by clicking the ‘Add property’ button. If you choose the new Domain option, you only need to add the domain name without www or subdomains. This option tracks everything connected to that domain. With the ‘old’ URL prefix option, you must add the correct URL, so with ‘HTTPS’ if you have an HTTPS website and with or without ‘www’. To collect the correct data, it’s essential to add the correct version:
You must verify that you’re the owner when you’ve added a website. There are several options to verify your ownership. The Domain option only works with DNS verification, while the URL prefix supports different methods. You can learn more about the differences in Google’s documentation: adding a new property and verifying your site ownership. You can also use Google’s Site Kit WordPress plugin to connect Analytics and Search Console while giving you statistics in your site dashboard.
Add to Yoast SEO
For WordPress users who use Yoast SEO, get the verification code via the ‘HTML tag’ method from the Ownership settings in Search Console. Copy the long, random string of characters.
You can easily copy the code and paste it into the Google field in the ‘Site connections’ section in the settings of your Yoast SEO plugin:
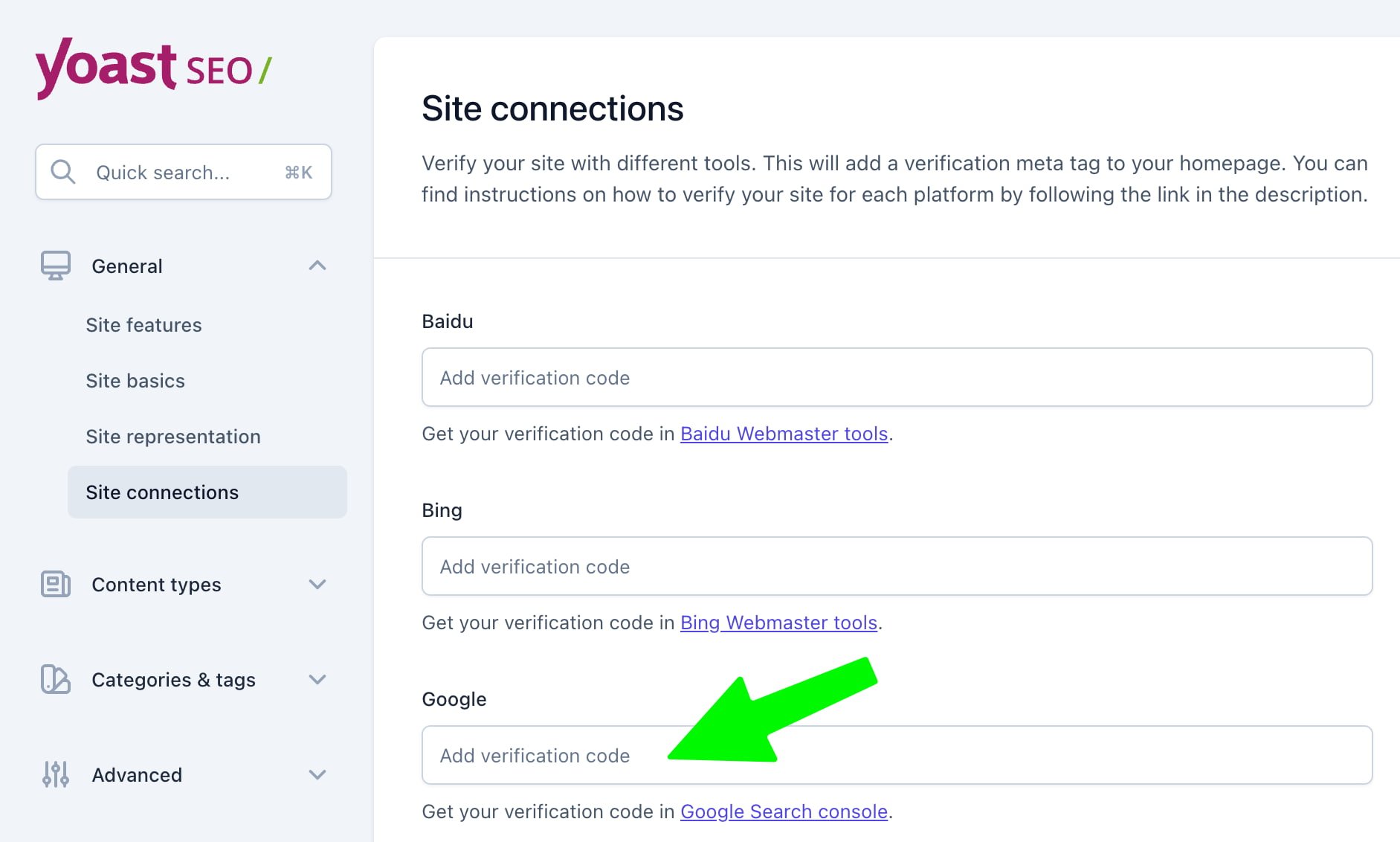
After saving this, you can return to Google Search Console and click the ‘Verify’ button to confirm. If everything is ok, you’ll get a success message, and GSC will start collecting data for your website.
Features in Google Search Console
Now that you’ve set up your account, what’s the next step? Well, it’s time to look at some of your data! In the rest of this article, we’ll explore some of the reports and information available.
Performance tab
In the Performance tab, you can see the pages and keywords your website ranks for in Google. If you’re eligible for that, you’ll also find reports on your content’s performance in Google Discover and on Google News. You’ll get 16 months of performance data for your reports.
If you check the performance tab regularly, you can quickly see what keywords or pages need more attention and optimization. So, where to begin? Within the performance tab, you see a list of ‘queries’, ‘pages’, ‘countries’, or ‘devices’. With ‘search appearance,’ you can check how your rich results are doing in search. You can sort each section by the number of ‘clicks’, ‘impressions’, ‘average CTR’, or ‘average position’. We’ll explain each of them below:
1. Clicks
The number of clicks tells you how often people clicked on your website in Google’s search results. This number can say something about the performance of your page titles and meta descriptions: if just a few people click on your result, your result might not stand out in the search results. It can be helpful to check what other results are displayed around you to see how you can optimize your snippet.
The position of the search result also impacts the number of clicks. If your page is in the top three of Google’s first result page, it will automatically get more clicks than a page that ranks on the second page of the search results.
2. Impressions
The impressions tell you how often your website or a specific page is shown in the search results. The number of impressions after this keyword shows how often our website is shown for that keyword in Google’s search results. You don’t know yet what page ranks for that keyword.
To see what pages might rank for the specific keyword, you can click on the line of the keyword. Doing this for a keyword, the keyword is added as a filter:
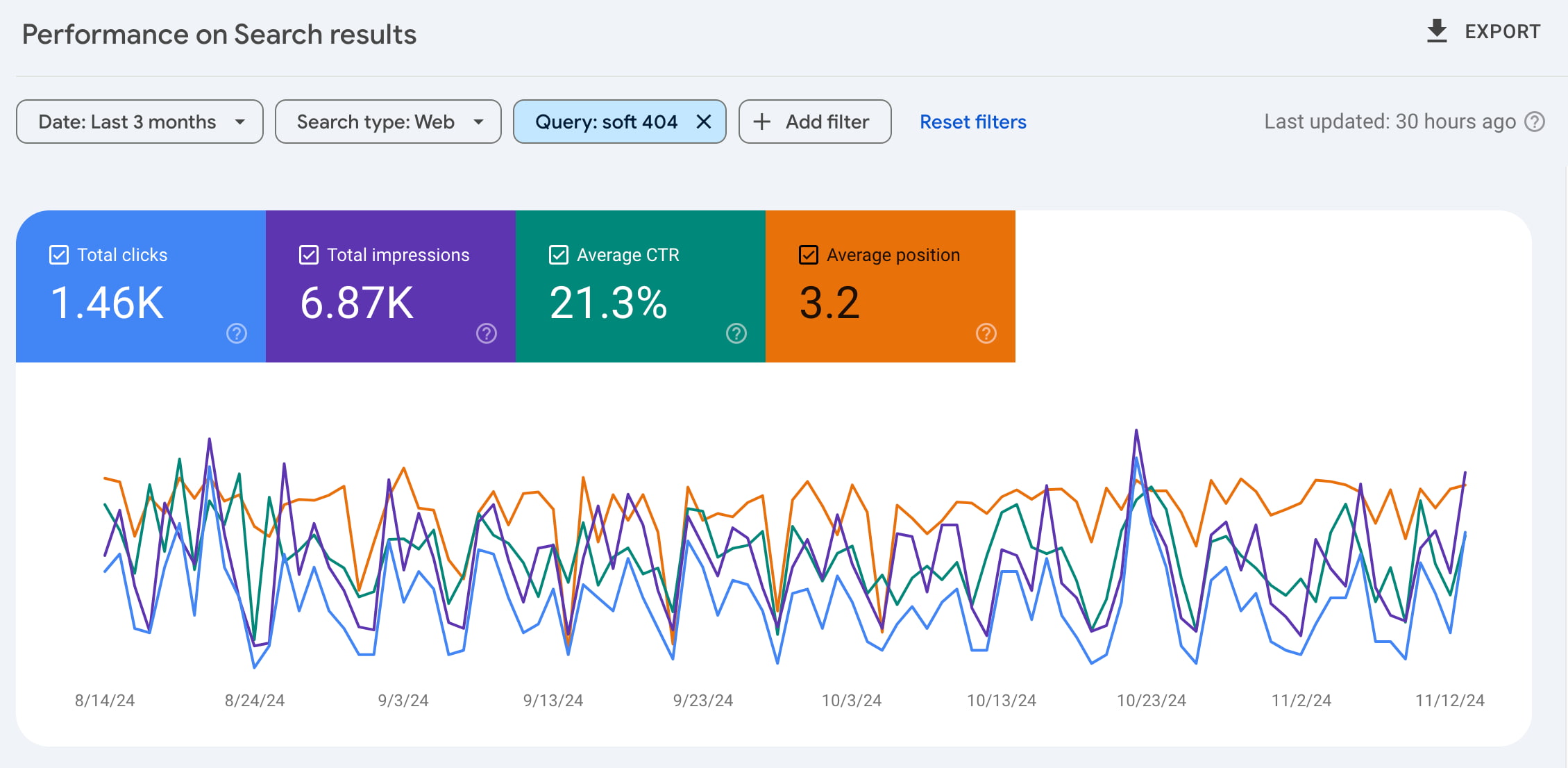
Afterward, you can navigate to the ‘Pages’ tab to see what pages rank for this keyword. Are those pages the ones you’d want to rank for that keyword? If not, you might need to optimize the page you’d like to rank. Think of writing better content containing the keyword on that page, adding internal links from relevant pages or posts to the page, making the page load faster, etc.
3. Average CTR
The CTR – Click-through rate – tells you what percentage of the people who have seen your website in the search results also clicked through to your website. You probably understand that higher rankings also lead to higher click-through rates.
However, you can also do things yourself to increase the CTR. For example, you could rewrite your meta description and page title to make it more appealing — Yoast SEO has AI features to help you do that. When the title and description of your site stand out from the other results, more people will probably click on your result, and your CTR will increase. Remember that this will not significantly impact you if you’re not ranking on the first page yet. You might need to try other things first to improve your ranking.
4. Average position
The last one on this list is the ‘Average position’. This tells you the average ranking of a specific keyword or page in your selected period. Of course, this position isn’t always reliable since more and more people seem to get different search results. Google seems to understand better and better which results fit which visitor best. However, this indicator still shows whether the clicks, impressions and average CTR are explainable.
Indexing
The’ Indexing’ section is a more technical but treasured addition to Google Search Console. This section shows how many pages have been in Google’s index since the last update, how many pages haven’t, and what errors and warnings caused Google to index your pages incorrectly. Google split this section into parts, collecting your regular pages and video pages while giving a home for your XML sitemap and the removals sections.
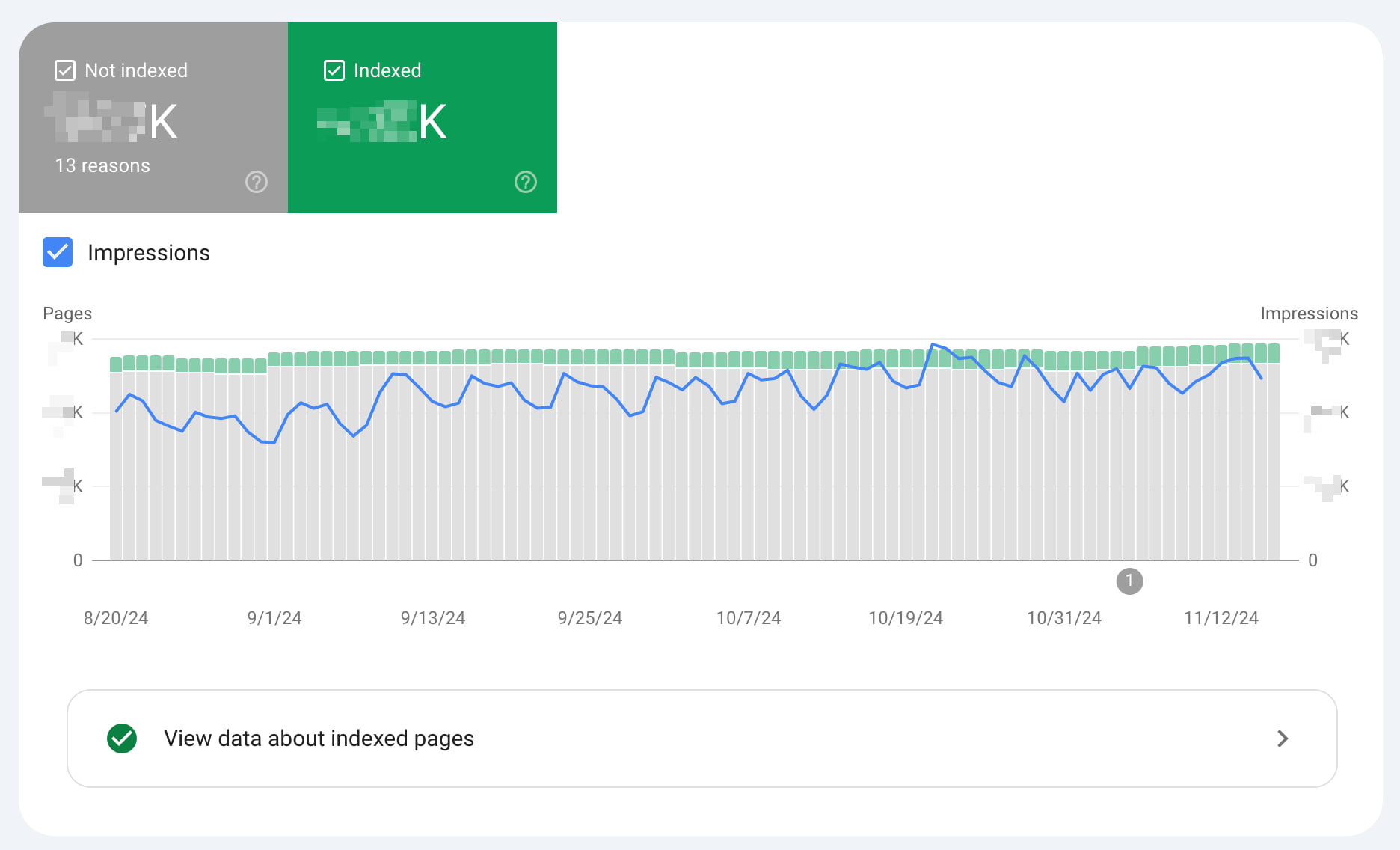
We recommend you check this tab regularly to see what errors and warnings appear on your website. However, you also get notifications when Google has found new errors. Please check the error in more detail when you get such a notification.
You may find that errors are caused when, e.g., a redirect doesn’t seem to work correctly, or Google finds broken code or error pages in your theme. You also find error messages like “Crawled – currently not indexed“. Google has a long list of possible reasons why pages aren’t indexed and what you can do to fix that.
Clicking on one of the issues, you can analyze the error more in-depth to see which specific URLs are affected. When you’ve fixed the error, you can mark it as fixed to make sure Google will test the URL again:
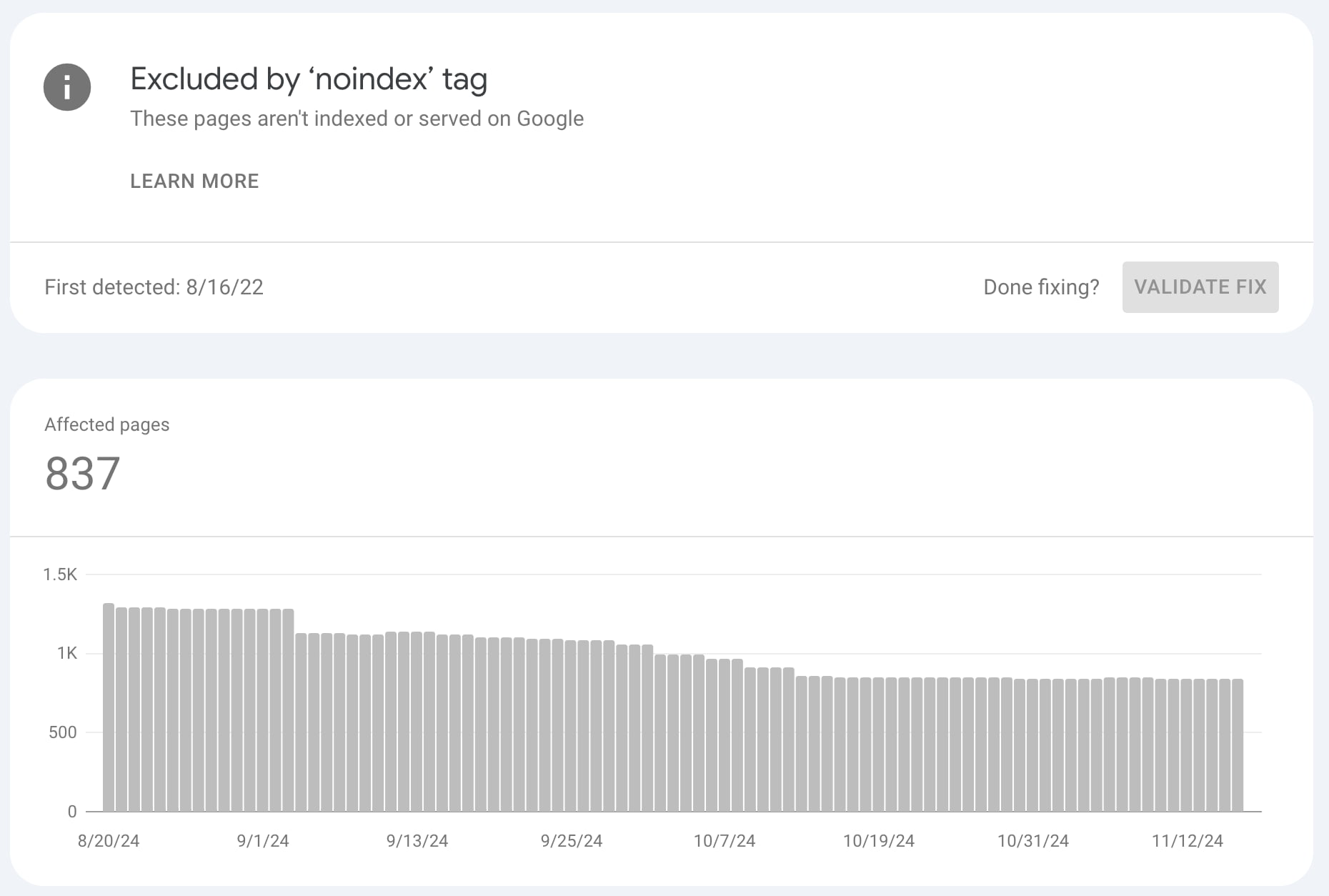
Things to look out for
There are a few things you should always look for when checking out your indexing coverage reports:
- If you’re writing new content, your indexed pages should steadily increase. This tells you two things: Google can index your site, and you keep your site ‘alive’ by adding content.
- Watch out for sudden drops! This might mean that Google is having trouble accessing (all of) your website. Something may be blocking Google, whether it’s robots.txt changes or server downtime. You need to look into it!
- Sudden (and unexpected) spikes in the graph might mean an issue with duplicate content (such as both www and non-www, wrong canonicals, etc.), automatically generated pages, or even hacks.
We recommend you monitor these situations closely and resolve errors quickly, as too many errors could signal low quality (poor maintenance) to Google.
URL Inspection
The URL Inspection tool helps you analyze specific URLs. You retrieve the page from Google’s index and compare it with the page as it lives now on your site to see if there are differences. You can also find more technical info on this page, such as when and how Google crawled it and how it looked at that moment. Sometimes, you’ll also notice several errors. This might be regarding Google’s inability to crawl your page correctly. It also gives information about the structured data found on this URL.
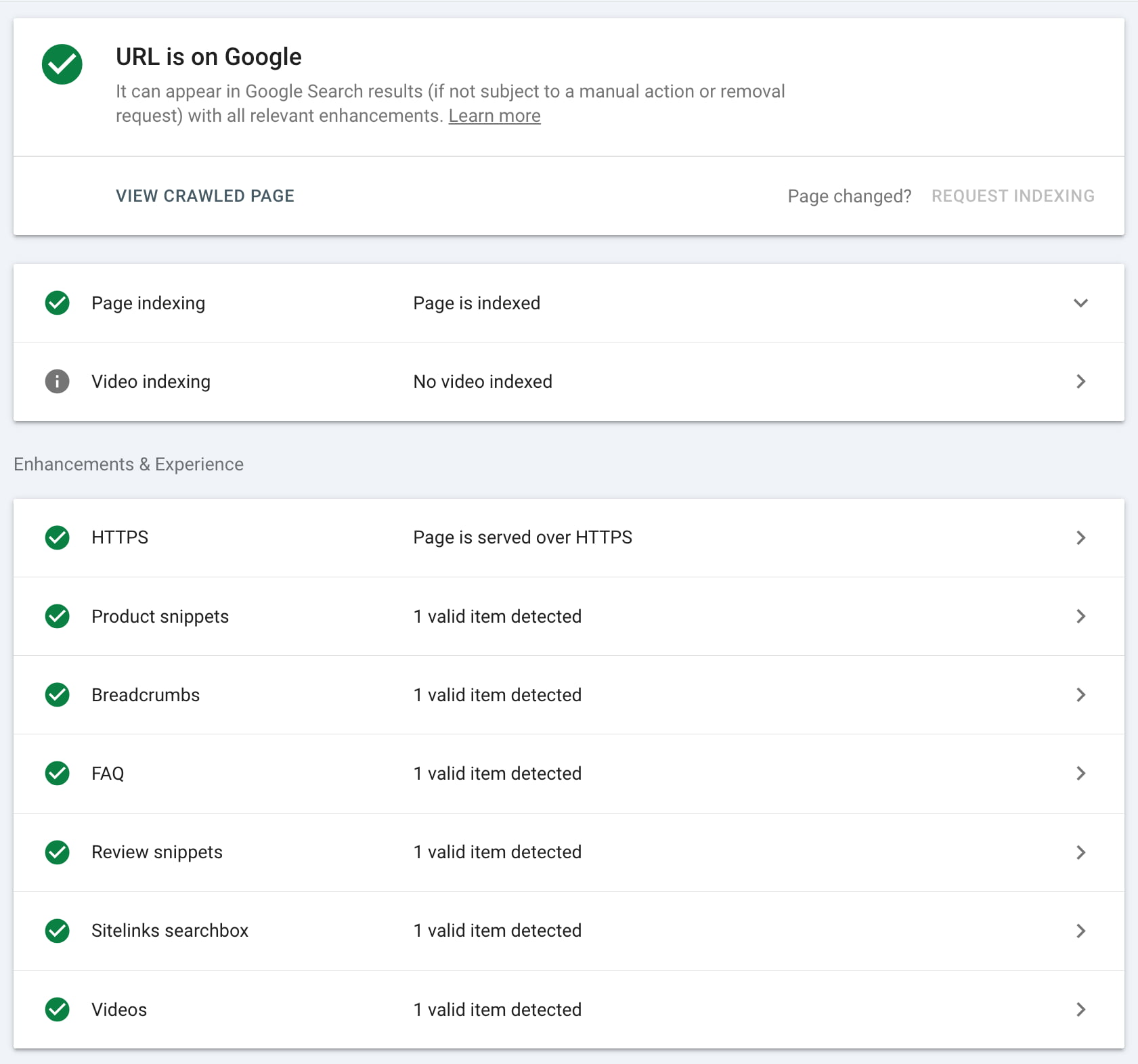
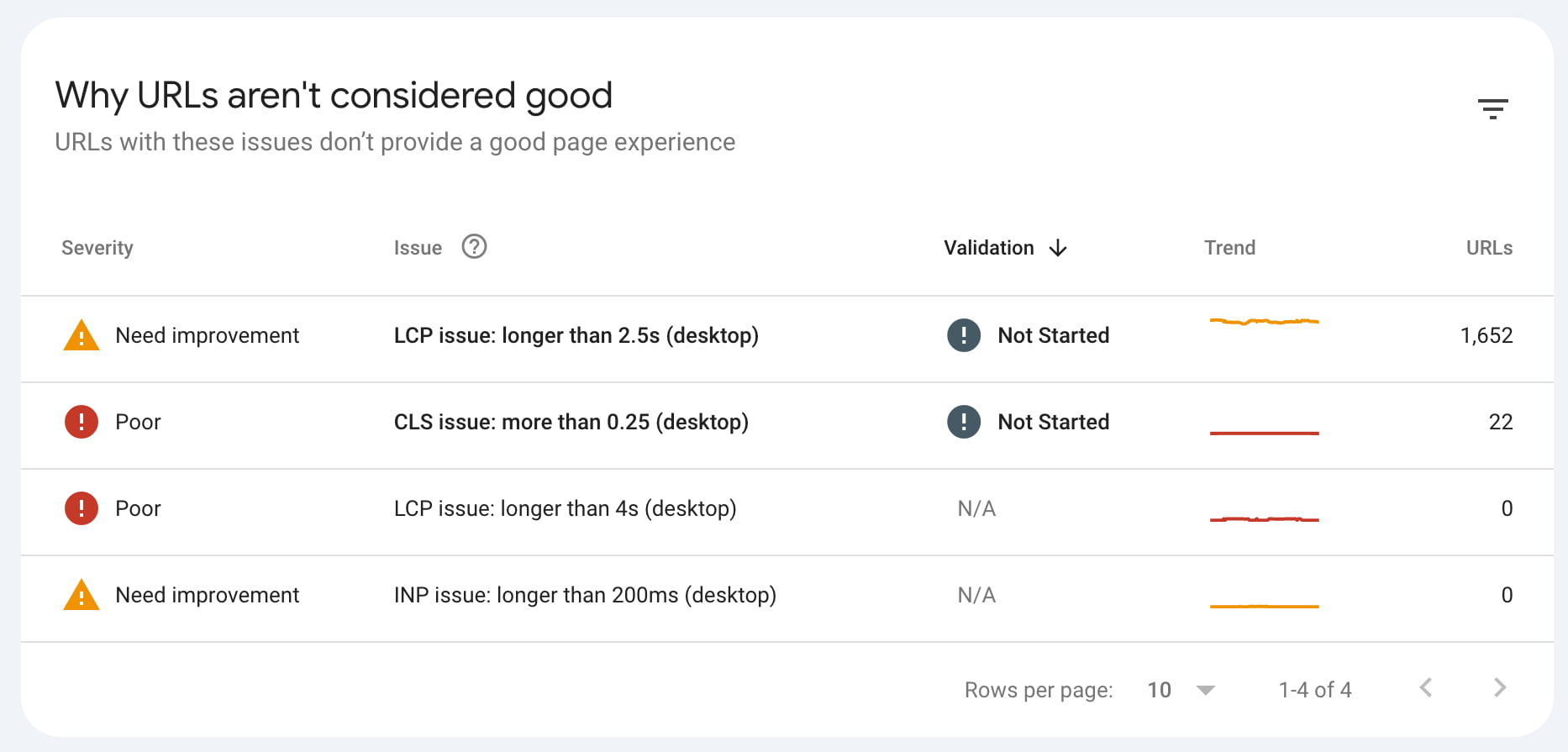
Experience
The experience report is an invaluable addition. It gives a good idea of how fast your site loads on mobile and desktop and how Google uses core web vitals to grade page experience. It shows which pages have issues that keep them from performing well. The data is based on the Chrome UX report, so it’s accurate data from real users.
Site speed, page experience, and user experience are complex topics with many moving parts, so it’s good to learn how to think about page speed. The answer is here: how to check site speed.
Enhancements: rich results
If you have structured data on your site — provided by Yoast SEO, for instance — it’s a good idea to check out the Enhancements reports in Search Console. The Enhancements tab collects all the insights and improvements that could lead to rich results. It lists all the structured data that Google found on your site. There’s an ever-expanding list of rich results, and you can find the following, among other things:
- Breadcrumbs
- Events
- FAQs
- Job postings
- Profile pages
- Review snippets
- Sitelinks searchboxes
- Videos
All these tabs show how many valid enhancements you have, and how many have errors or warnings. You get details about the kind of errors and warnings, and on which URLs these are found. There’s also a trend line that shows whether the number of issues is increasing or decreasing. And that’s just the start of it.
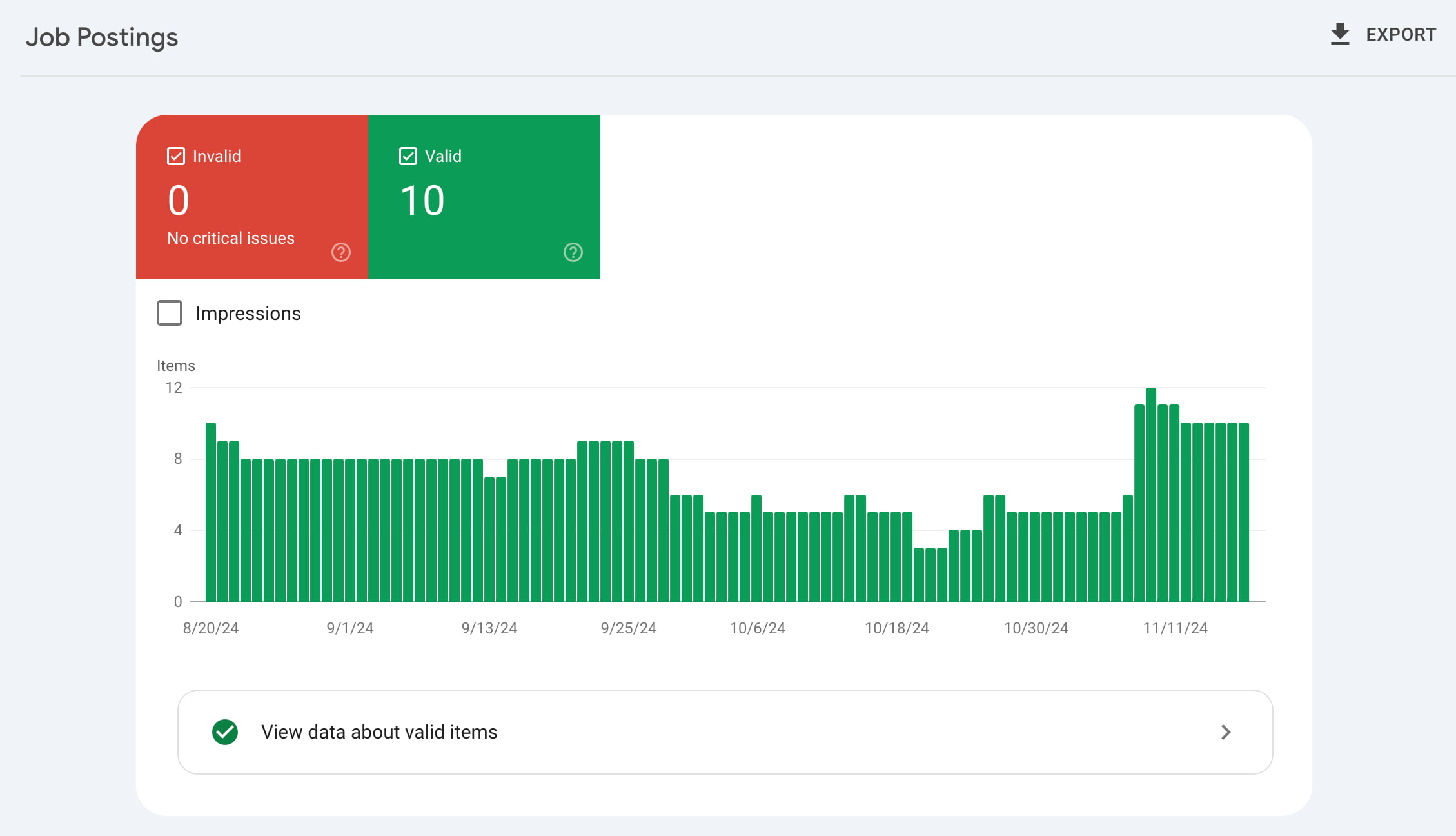
The Enhancements reports help you find and fix issues that hinder the performance of your rich results in search. By checking the issues, reading the support documentation, and validating fixes, you can increase your chance of getting rich results in search. We have a more expansive guide on the structured data Enhancement reports in Google Search Console.
Sitemaps
An XML sitemap is a roadmap to all important pages and posts on your website. Every website would benefit from having one. Do you run the Yoast SEO plugin on your website? Then, you automatically have an XML sitemap. If not, we recommend creating one to ensure Google can easily find your most important pages and posts.
You can find an option for XML sitemaps within the Indexing tab of Google Search Console. Here, you can tell Google where your XML sitemap is located on your site:
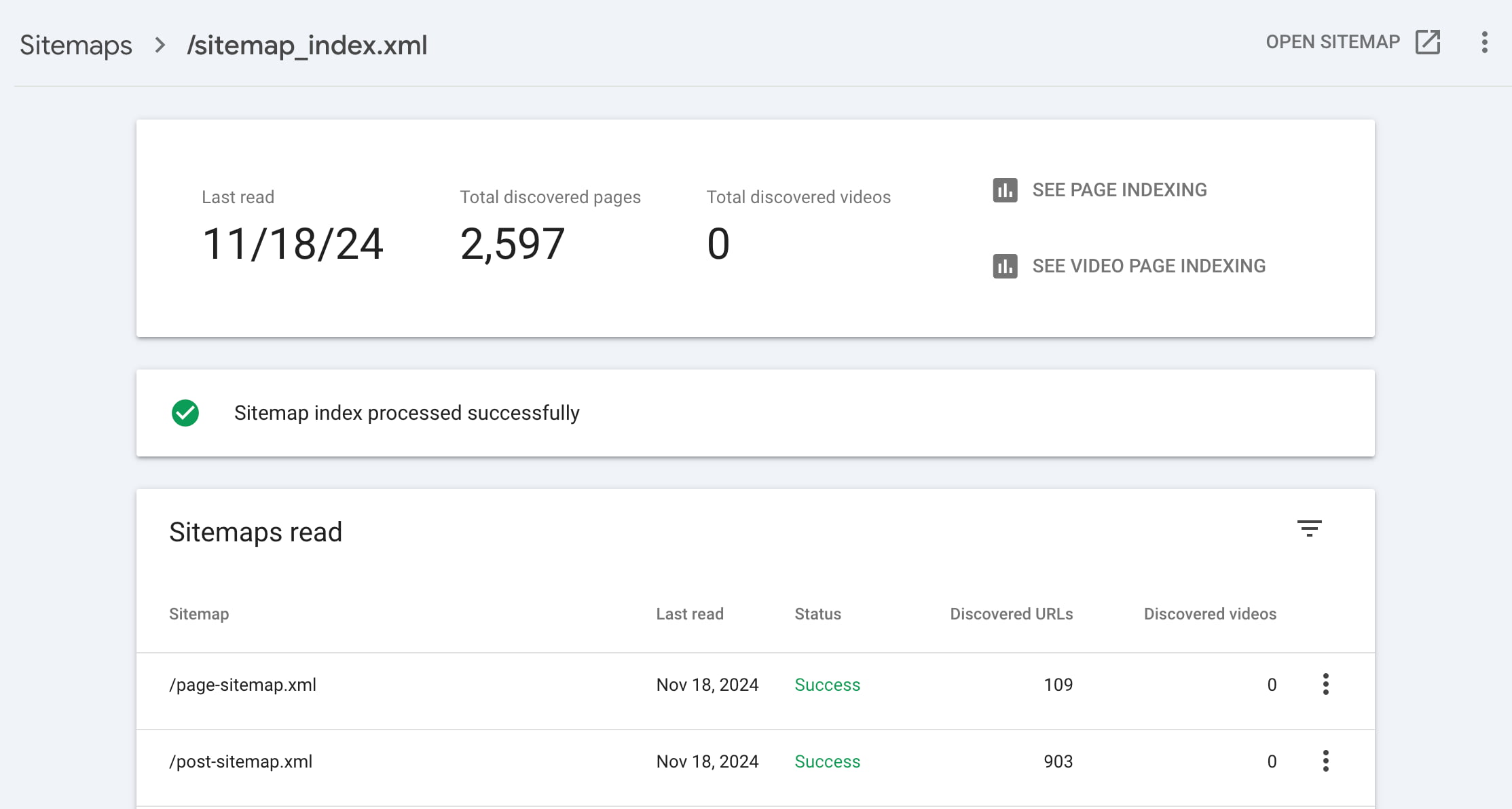
We recommend that everyone enter the URL of their XML sitemap into GSC to make it easy for Google to find. In addition, you can quickly see if your sitemap gives errors or if some pages aren’t indexed. Regularly checking this ensures that Google can find and read your XML sitemap.
We recommend regularly checking the XML sitemap section in our plugin to manage which post types or taxonomies you include in your sitemaps!
Shopping
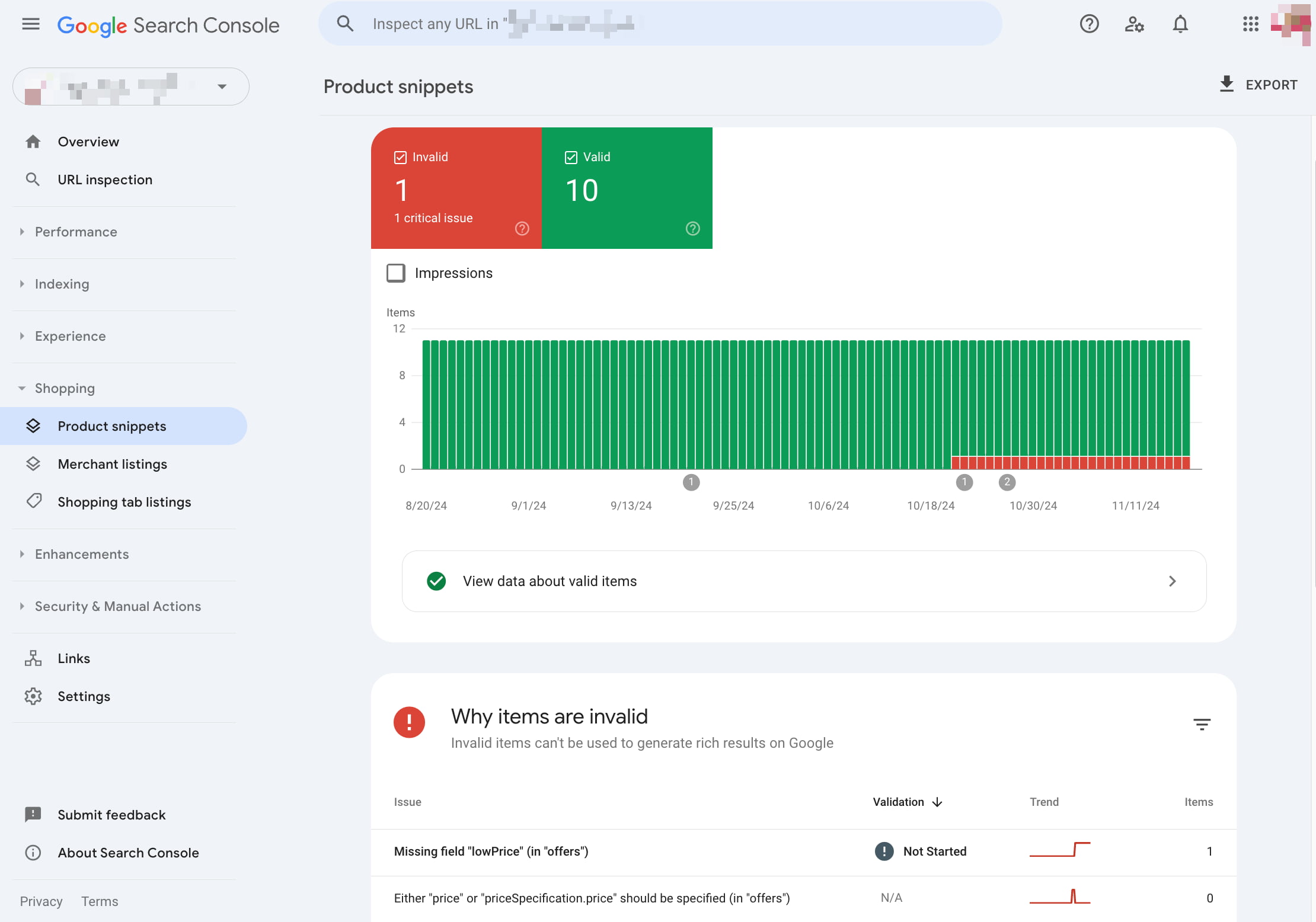
Google Search Console also has a Shopping section. Here, you can check how Google sees your products and if they get proper rich results. You’ll see if they are valid or if they are missing fields that make the product snippets more prominent. Click on a product to see which fields are missing for particular products and if these are essential parts or nice-to-haves. If you’ve added these to the structured data of your products, you can validate the fix in Search Console.
In the Shopping section, you’ll also find your Google Merchant listings and an option to enable shopping tab listings to show your products on the Shopping tab in Google Search. With these options, Google gives ecommerce site owners — and people selling stuff — more ways of checking how their listings are doing.
Links
Within the links to your site section, you can see how many links from other sites are pointing to your website. Besides, you can see which websites link, how many links those websites contain, and what anchor texts are used most when linking to your website. This can be valuable information because links are still vital for SEO.
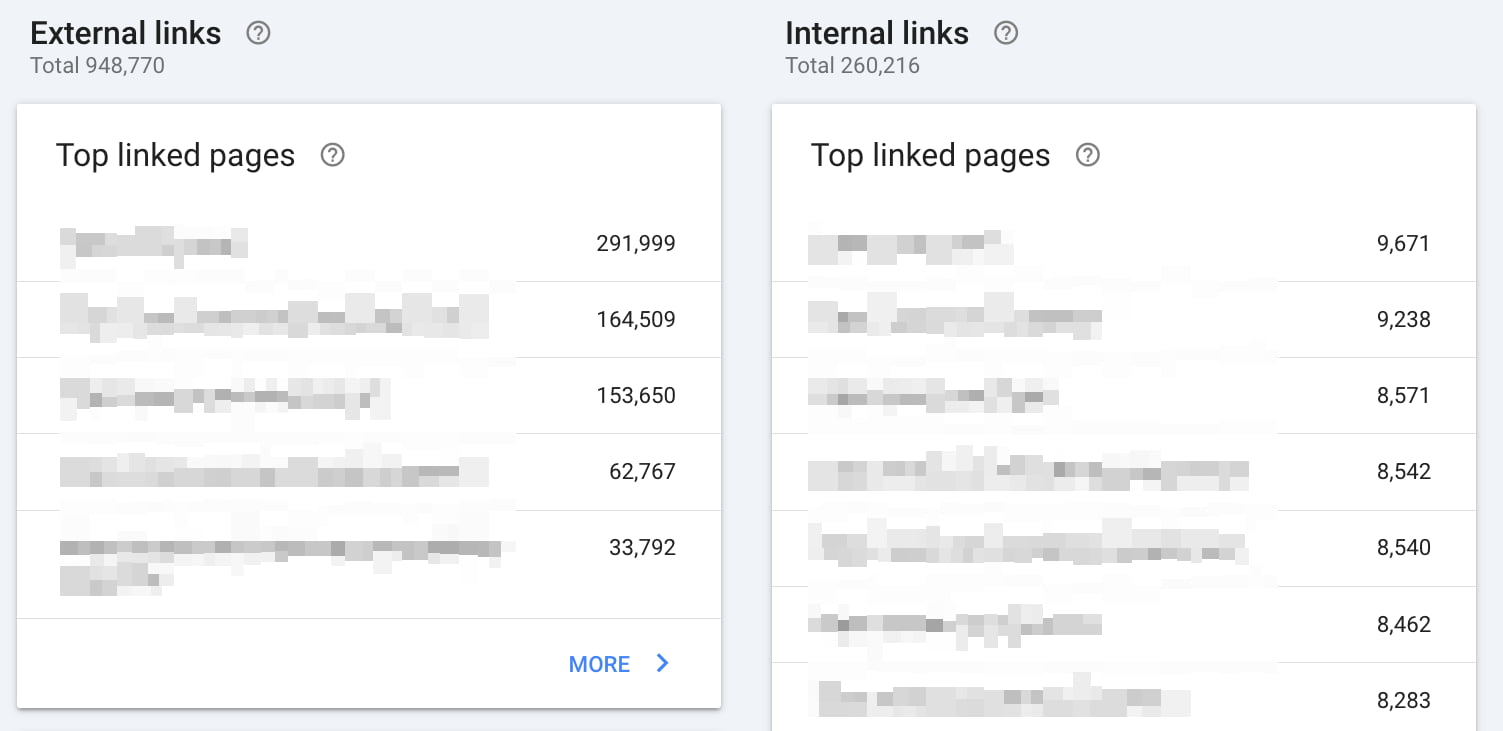
Within the internal links section, you can check what pages of your website are most linked to from other spots on your site. This list can be valuable to analyze regularly because you want your most important pages and posts to get the most internal links. By doing this, you make sure Google understands your cornerstones as well.

Manual Actions
You don’t want to see anything in the manual actions tab. If Google penalizes your site, you’ll get more information. If your site is affected by a manual action, you’ll also get an email message.
Several scenarios can lead to these kinds of penalties, including:
- You have unnatural/bought links
Ensure links from and to your site are valuable, not just for SEO. Preferably, your links come from related content that is valuable for your readers. - Your site has been hacked
A message stating your site’s probably been hacked by a third party. Google might label your site as compromised or lower your rankings. - You’re hiding something from Google
If you’re ‘cloaking’ (that is, intentionally showing different content to users to deceive them), or using ‘sneaky’ redirects (e.g., hiding affiliate URLs), then you’re violating Google’s guidelines (now known as Google Search Essentials). - Plain Spam
Automatically generated content, scraped content, and aggressive cloaking could cause Google to blocklist your site. - Spammy structured markup
If you use rich snippets for too many irrelevant elements on a page or markup content hidden from the visitor, that might be considered spammy. Mark up what’s necessary and only the necessary things.
Security issues
Within the security issues tab, you’ll get a notification when your website seems to have a security issue.
Google Search Console is essential
Reading this post should give you a good idea of what Search Console is capable of and how to use it, so we’d like to ask you this: Do you already use Google Search Console for your website? If not, create an account to collect data about your website. Do you think something is missing? Feel free to leave a comment!
Read more: How to make your site stand out in the search results »
