Closing a spider trap Fix crawl inefficiencies

Quite some time ago, we made a few changes to how yoast.com is run as a shop and how it’s hosted. In that process, we accidentally removed our robots.txt file and caused a so-called spider trap to open. In this post, I’ll show you what a spider trap is, why it’s problematic and how you can find and fix them.
What is a spider trap?
A spider trap is when you create a system that creates unlimited URLs. So Google can spider a page and find 20 new URLs on it. If it then spiders those 20 URLs, it finds 20 * 20 new URLs. If it then spiders those 400 URLs, it finds 400 * 20 = 8,000 new URLs. This escalates quickly, as you can see. If each and every one of these URLs was unique and wonderful, this would not be a problem, but usually, they’re not. So, this causes a massive duplicate content problem.
A spider trap is bad for your SEO because every time Google crawls (or “spiders”) a page in your trap, it’s not crawling actual content on your site. Your new, high quality, super-valuable content might get indexed later, or not at all, because Google is spending its precious time in your trap. And the content it is crawling is deemed as duplicate and lessens how Google sees your site overall. This is why solving spider traps is important for SEO, and especially if you’re thinking about crawl budget optimization.
What do spider traps look like?
Our spider was one of a very particular type. We have a tool here on yoast.com called Yoast Suggest. It helps you mine Google Suggest for keyword ideas. When you enter a word into it, it returns the suggestions Google gives when you type that word into Google. The problem is: Google, when given a search box, will start throwing random words into it. And the results then have links for more results. And Google was thus trapping itself.
You might think that this is a nice story and spider traps never happen in real life. Unfortunately, they do. Faceted navigation on webshops often creates hundreds of thousands of combinations of URL parameters. Every new combination of facets (and thus URL parameters) is a new URL. So faceted navigation done poorly very often results in trapping the spider.
Another common cause of spider traps is when a site has date pages. If you can go back one day, to get a new date, and then back, and back, and back, you get a lot of pages. In my time as a consultant for the Guardian, we found Google spidering a date in the year 1670. It had gone back through our online archives, which went back almost 20 years at that point, to find nothing for more than 300 years…
How to recognize a spider trap
The easiest way to recognize a spider trap is by looking at your access logs. These logs contain a line for every visit to your site. Now as you can imagine, on larger sites your access logs get big very quickly. Here at Yoast, we use a so-called ELK-stack to monitor our website’s logs, but I’ve personally also used an SEO log file analyzer by Screaming Frog to do this.
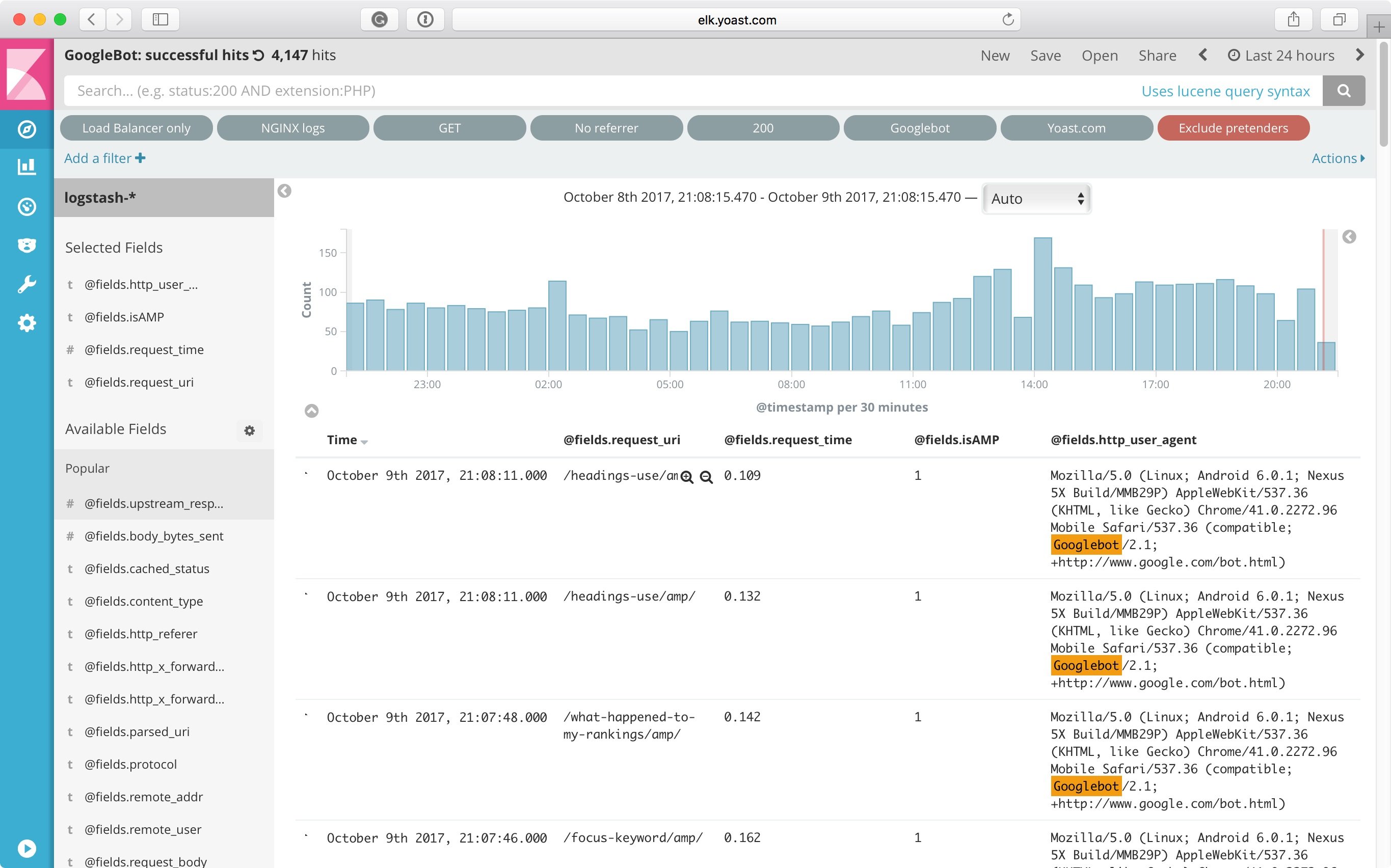
What you’re looking to do is look at only Googlebot‘s visits, and then start looking for patterns. In most cases, they’ll jump straight at you. It’s not uncommon for spider traps to take up 20-30% or even larger chunks of all the crawls. If you can’t find them immediately, start grouping crawls, looking for patterns within URLs. You can start from the beginning of the URL, provided you have clean URLs. If your URLs are slightly more cumbersome, you’ll have to create groups manually.
An ELK stack makes this very easy because you can search and segment quickly:
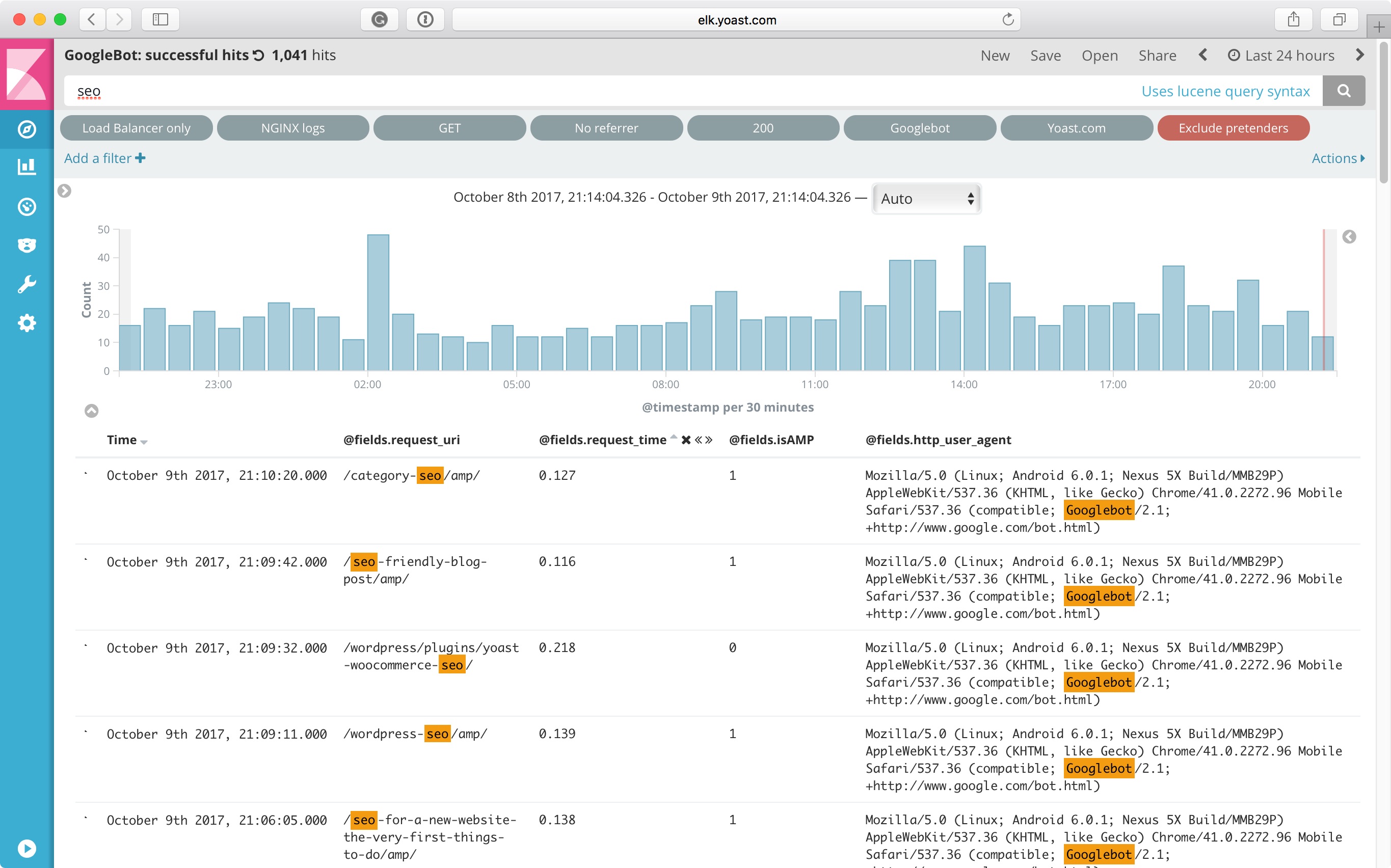
How do you solve a spider trap?
Solving a spider trap can be a tricky thing. In our case, we don’t want /suggest/ to be indexed at all, so we just blocked it entirely with robots.txt. In other cases, you cannot do that as easily. For faceted navigation, you have to think long and hard about which facets you’d like Google to crawl and index.
In general, there are three types of solutions:
- Block (a section of) the URLs with
robots.txt. - Add
rel=nofollowandnoindex,followon specific subsets of links and pages and userel=canonicalwisely. - Fix the trap by no longer generating endless amounts of URLs.
In the case of the Guardian, we could simply prevent linking to dates where we had no articles. In the case of Yoast.com’s suggest tool, we simply blocked the URL in robots.txt. If you’re working with faceted search, the solution is, usually and unfortunately, not that simple. The best first step to take is to use a form of faceted search that doesn’t create crawlable URLs all the time. Checkboxes are better than straight links, in that regard.
In all, finding and closing a spider trap is one of the more rewarding things an SEO can do to a website. It’s good fun, but can certainly also be hard. If you have fun examples of spider traps, please do share them in the comments!
Read more: Robots.txt: the ultimate guide »

I have a doubt since a long time. What is the use of robot.txt.
Tell me exactly.
Spider trap is a common problem of websites with search function. Often developers forget that these pages should not be crawled and indexed by search engines. This leads to one of the most common, and potentially the worst, spider trap issues as it sometimes allows others to easily add indexable content to your website without even being logged in.
Fortunately, on most websites this one is easy to fix and this is how I’ve addressed it in the past.
– Add noindex, nofollow meta data to search result pages and get the site re-crawled, this should hopefully remove some the results from the search engine result pages. You also have the option of manually removing pages via Google Webmaster Tools
– Once the site has been recrawled and the offending pages have dropped out of the index I like to block the pages via Robots.txt to prevent further crawling
I learn something with SEO everyday! I have never heard of a spider trap before but its great to know what it is and how to prevent it from happening in the first place! Great post Yoast!
Great post as ever Yoost! Very interesting to learn that a site I visit as a user every day (the Guardian) suffers from an issue I deal with professionally, yet I’d have never spotted it as I’ve never had a need to crawl the site! We’ve found loads of different causes of spider traps over the years, most are caused by poorly-developed relative URL logic or the dreaded faceted nav structures you refer to! There’s a good extension to this topic covered in one of our blogposts over at https://www.wolfgangdigital.com/blog/fixing-spider-traps which I hope you don’t mind me referring to as it’s bang on topic here and supports pretty much every point you’ve made here!
Keep up the great work, wish I’d seen the original Facebook poll now as this is a topic close to my heart and I would’ve suggested it too! :)