The history of Schema: towards an easy to understand web

Today, it seems that everyone is talking about Schema as being the next hot thing. It has a rich history, and it took a long while for it to gain momentum. Talk of a machine-readable web started when the internet was still in its infancy. It was Sir Tim Berners-Lee — the computer scientist best known as the inventor of the World Wide Web — himself who dreamt of a place full of readable data, neatly linked. Years later, we are working towards that goal, thanks to a vocabulary called Schema. This article tells you a bit more about how we got here.
Before we begin: we know that Schema, structured data and rich snippets can feel a bit technical from time to time. What are they, how do you use them and what can you do with them? To help you better understand what rich results can bring you, we’ve enlisted the help of someone special. So, meet your guide here at Yoast when it comes to structured data:
Meet Rich Snippet
Hi, the name is Rich Snippet! Just like the rich snippets in Google, I love to stand out. And this is exactly how rich snippets work: we’re visual, cool and hard to miss. Which is why we get way more clicks than normal search results.
Don’t worry, you don’t have to copy my exact style (not everyone can pull off this awesome suit). I’m just here to tell you that it pays off to stand out, with rich snippets of your own!

Back to the future
In 1989, Tim Berners-Lee wrote a proposal on how he thought CERN — the European Organization for Nuclear Research — could prevent loss of information. He suggested a ‘mesh’ or a web of links of available knowledge in CERN and who’s responsible for what. His proposal struck a chord, and Berners-Lee was commissioned by CERN to build this system. This would evolve into a little-known thing called the World Wide Web. Of course, he also made the markup language HTML and the software to ‘browse’ the web.

.jpg){kind=link}
In his initial proposal, Berners-Lee makes it clear that it’s not just about linking information. It is just as essential to have information about what these links mean and to form connections from these. He also explicitly states that:
“We should work toward a universal linked information system, in which generality and portability are more important than fancy graphics techniques and complex extra facilities.”
Tim Berners-Lee
Berners-Lee might not have been aware of it at the time, but his proposal was the start of something big. Something most of us can’t imagine life without. And although his initial focus was not on fancy graphics, they did manage to sneak in when more people got involved.
Fast-forward
Years later, the rapid development of the web attracted not only millions of users but also companies with a plan. Many of these companies started to contribute to the web with technologies. Soon, the internet grew from a place built on a few simple building blocks, to an extensive and way more complex network. Not only that, but the web also became a place not only visited by a simple browser on a desktop machine but many devices — including voice assistants.
In all of this, search engines increasingly had trouble discovering meaning from these ever-complex pages. Also, the tidal wave of content coming at search engines made it imperative for them to find a way to help with classifying and tagging knowledge.
The Semantic Web
In 1999, Berners-Lee dreamt up the original concept of the Semantic Web in the book Weaving the Web:
“I have a dream for the Web in which computers become capable of analyzing all the data on the Web — the content, links, and transactions between people and computers. A “Semantic Web,” which makes this possible, has yet to emerge, but when it does, the day-to-day mechanisms of trade, bureaucracy, and our daily lives will be handled by machines talking to machines. The “intelligent agents” people have touted for ages will finally materialize.”
Two years later, Tim Berners-Lee published an article in the Scientific American (behind a paywall, unfortunately) finetuning the concept of the Semantic Web, kicking off a slew of developments on this front. In 2006, Berners-Lee appended that with the idea of Linked Data:
“The Semantic Web isn’t just about putting data on the web. It is about making links so that a person or machine can explore the web of data. With linked data, when you have some of it, you can find other, related, data.”
The goal of the Semantic Web is to make the web machine-readable. For this, context had to be added to HTML to make sense of all the different elements on a page. Without these tags supporting metadata, machines have a hard time getting reliable answers from the content. Now, thanks to standards like RDF — or, Resource Development Framework, we’ll get there in a minute — you can describe elements to machines — this article is written by an author by the name of Edwin Toonen, who works for Yoast.
Since HTML is limited to describing documents and the links between them, there needs to be an additional step before browsers can make sense of the semantics. Semantic Web Technologies like RDF, OWL, and XML can describe the contents of the HTML — like the article, author name and works for mentioned above.

A predecessor: RDF
During the late 90s, several frameworks for describing information saw the daylight. Companies introduced some with a specific goal, and others were meant to be used within a particular environment. None, however, was developed as a standard with a broad application — until the W3C stepped in.
The web standards body W3C — headed by Tim Berners-Lee, yes, him again —, proposed the Resource Development Framework, RDF for short. This is a practical method for describing or modeling information found in web resources and making these machine-understandable.
The goal of frameworks like RDF is to help build knowledge graphs. A knowledge graph is a network interconnected with descriptions of entities. These entities are real-world objects, events, situations, or abstract concepts. Together this forms a system of data for machines to interpret.
They can be as simple as the one below:
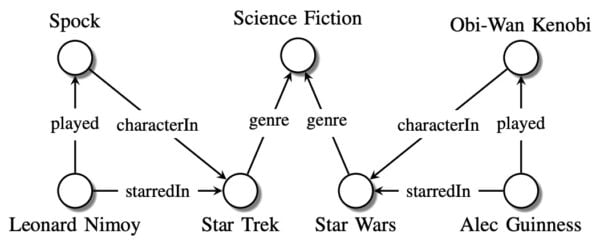
To build knowledge graphs, descriptions need to be added to the HTML, and this can be done via several data serialization formats, such as JSON-LD and RDF/XML. Later, other types of notation syntaxes saw the daylight, like RDFa, which helped embed the rich metadata in HTML documents.
RDF uses triples to explain a piece of information in a statement: object-predicate-subject. This made it incredibly powerful, but also unnecessarily complicated for many general purposes.
Wikipedia explains it well: “The subject denotes the resource, and the predicate denotes traits or aspects of the resource and expresses a relationship between the subject and the object. For example, one way to represent the notion “The sky has the color blue” in RDF is as the triple: a subject denoting “the sky”, a predicate denoting “has the color”, and an object denoting “blue”. Therefore, RDF uses subject instead of object (or entity) in contrast to the typical approach of an entity–attribute–value model in object-oriented design: entity (sky), attribute (color), and value (blue).”
RDF was a bit misunderstood at the time and, in part thanks to an ever-expanding list of spinoffs, failed to become the de-facto standard it was supposed to become.
Other syntaxes
In the early 2000s, another syntax for describing metadata appeared: Microformats. This was introduced by the WHATWG HTML working group and proposed a much simpler view of the Semantic Web. It is based on several existing standards but used an easier to understand format. The goal was to “write stuff once”, and add context to human-readable content. Unfortunately, the Microformats syntax was unambitious and lacked expandability. Plus, by tying the human-readable content together with the machine-readable code things became fragile. It became harder and harder to maintain both and to fix things whenever something changed. In the example below, you can see how complex code becomes with Microformats:
<div itemscope itemtype="http://schema.org/Article">
<span itemprop="name">How to Tie a Reef Knot</span>
by <span itemprop="author">John Doe</span>
This article has been tweeted 1203 times and contains 78 user comments.
<div itemprop="interactionStatistic" itemscope itemtype="http://schema.org/InteractionCounter">
<div itemprop="interactionService" itemscope itemid="http://www.twitter.com" itemtype="http://schema.org/WebSite">
<meta itemprop="name" content="Twitter" />
</div>
<meta itemprop="interactionType" content="http://schema.org/ShareAction"/>
<meta itemprop="userInteractionCount" content="1203" />
</div>
<div itemprop="interactionStatistic" itemscope itemtype="http://schema.org/InteractionCounter">
<meta itemprop="interactionType" content="http://schema.org/CommentAction"/>
<meta itemprop="userInteractionCount" content="78" />
</div>
</div>When Google introduced rich snippets — the highlighted search results for things like facts, movie times, events, et cetera — in May 2009, the two syntaxes used to get these rich snippets were Microformats and RDFa. Starting from 2015 onwards, Google started to prefer a third syntax: JSON-LD.
JSON-LD, or JavaScript Object Notation for Linked Data, is a method of describing linked data using JSON. JSON-LD is a code snippet that helps describe your content for search engines. You can describe what price belongs to what product, or what zip code belongs to what company. Basically, instead of adding semantic attributes to individual elements on a page, you’re providing a small block of JavaScript code that has all that info — including all the connections. This proved to be an essential piece of the Schema puzzle.
That example you saw above, now in JSON-LD:
<script type="application/ld+json">
{
"@context": "http://schema.org",
"@type": "Article",
"author": "John Doe",
"interactionStatistic": [
{
"@type": "InteractionCounter",
"interactionService": {
"@type": "WebSite",
"name": "Twitter",
"url": "http://www.twitter.com"
},
"interactionType": "http://schema.org/ShareAction",
"userInteractionCount": "1203"
},
{
"@type": "InteractionCounter",
"interactionType": "http://schema.org/CommentAction",
"userInteractionCount": "78"
}
],
"name": "How to Tie a Reef Knot"
}
</script>Easy to understand for both humans and machines!
2011: the introduction of Schema.org
One of the reasons why previous structured data formats didn’t get a foothold is the lack of a common vocabulary shared across search engines. This made it hard to add something to your site that any search engine could understand, which in turn made it hard for search engines to promote adding it. Also, the available solutions failed in truly achieving that linked data objective. That’s why on June 2, 2011, Google, Bing, and Yahoo! collectively announced Schema.org. Yandex joined the initiative in November 2011.
Thanks to Schema, there’s now a shared vocabulary among search engines — readable not just for crawlers, but also applications and other data formats. Of course, search engines might read the content a bit differently, or they might support fewer pieces, but it’s immensely valuable nonetheless. With the introduction of Schema came a large number of new types, from movies to products, plus the possibility to extend it, if anyone wanted to do so.
The development of Schema is out in the open, as it should. In every release, new types are being added, improved, or expanded, often based on input for external parties. In September 2011, a new set of news related properties saw the daylight. November 2012, Schema.org joined hands with the GoodRelations project to bring a broad set of eCommerce related types to the vocabulary. After that, it gradually expanded with more and more properties.
In 2013, Schema added actions to the project. This makes it possible not just to describe something but also to append a response to it. So, you’re not just filling in the opening hours of a restaurant but making the reservation an action as well. It’s only one of many new applications of this shared vocabulary.
Schema today
Over the years, the adoption of Schema grew faster and faster. Search engines adopted evermore types and turned their insights into the content into ever richer rich results. Schema structured data powers many of the latest rich results, and there’s no end in sight. Also, its role is expanding. Today, we also see Schema actively help search engines make sense of historical events like COVID-19 by offering specific types to describe these events. Schema is now a key part of SEO, as rich results can help you ‘bypass’ the conventional ranking ladder.
Today, however, it’s mostly just Google managing and contributing to Schema, as Yahoo/Yandex, et cetera aren’t part of the landscape. Google is strategically focused on expanding support and features for Schema markup, as it helps them to better understand the web — which in turn helps them to deliver better services, voice results, ads, et cetera.
After Google adopted JSON-LD as the preferred notation syntax, implementing structured data became easier as well. In the classic notation syntax, metadata had to be embedded in the HTML, making it difficult to add. The code became unwieldy and error-prone. JSON-LD made it possible to take the description out of the content, so to say, making it possible to properly link all the different elements together — on our way to a web of linked data.
The history of Schema
The history of Schema is a quest for a machine-readable web — a semantic web. By describing your content with Schema, you are actively helping machines make sense of the web — helping you get better results. While structured data has come a long way, its best years are still ahead. There is a lot more to come!
Curious to learn more? We’ve launched an Understanding structured data training course! In this course, we explain what structured data is in detail and how you can improve your chances of getting your own rich results. Get access to this Understanding structured data course by going Premium! This also gives you access to all of our other SEO courses and extra features in Yoast SEO.
A quick recap by Rich:
It seems that Schema is here to stay. And will become more important along the way. So, if SEO is part of your marketing strategy, we have to get you some rich results of your own!
To increase your chances at rich snippets that will help you stand out, make sure to add structured data to your content. If you’re not already doing this, Yoast SEO can help you!

Read more: The ultimate guide to structured data with Schema.org »

I am using yoast plugin in my website but facing one problem. Can’t see my local organization information on google. Infact, I am using the feature available in yoast wordpress plugin.
Please suggest some solution for this.
Thanks
Hi Kavita, Sorry for the inconvenience. Not sure if we completely understand what’s going wrong. Which feature do you use exactly?
I love Yoast Schema blocks – in fact, I have 300+ pages with FAQ schema blocks on them!
For debugging purposes, I need to disable the schema output on those pages.
Per Yoast support, I tried add_filter( ‘wpseo_schema_needs_faq’, ‘__return_false’ ); in functions.php – but it did not work.
Support did not offer any other suggestions, so I am hoping you can help me.
Respectfully.
Hi! Thanks for your comment. That’s strange, because that function should work. Could you double check it to see if you’ve entered it correctly? Here’s what it looks like: https://yoast.com/app/uploads/2020/08/schema-faq-filter.png
Here’s the email from Google Search Console team when you disable schema output using the filter add_filter( ‘wpseo_schema_needs_faq’, ‘__return_false’ ); in functions.php:
FAQ issues detected on :
Search Console has identified that your site is affected by 1 FAQ issues:
Top Errors
Errors can prevent your page or feature from appearing in Search results. The following errors were found on your site:
Missing field “mainEntity”
We recommend that you fix these issues when possible to enable the best experience and coverage in Google Search.
I did get it to remove the schema output!…but it still shows as a FAQ page in GSC…which causes GSC to yell at me because I’ve got a FAQ page without any schema. Do you have any specific code for removing the the FAQ page identifier?
Thank you so much!
Thank you so much for sharing in detail the article, this has sorted out all my queries.
Here one thing I would like to know that is I am using Classic editor and FAQ schema is not available, could you please help me to get the same.
Hi. The block editor is a great tool for both developer as well as users. For instance, it helps us build awesome tools more quickly. For you as a user, it offers an easy way to build your pages using advanced tools like these FAQ blocks. Unfortunately, getting this to work in the classic editor — and to make it easy to work with — is hard. For now, we’ve chosen to focus on the block editor. Please try it, it’s pretty awesome :)
Thank you for making this content but I am facing problem with schema markup. It is showing that you don’t have schema markup in your blog.
Hi Samir. I’m not sure what you mean. If you open the source of our page, you’ll notice a lot of schema markup for our site — all generated by Yoast SEO! You can also check the link Christopher added above.
https://search.google.com/structured-data/testing-tool/u/0/#url=https%3A%2F%2Fyoast.com%2Fhistory-of-schema%2F
Leaving out Schema.org’s most immediate twin predecessors, http://www.productontology.org/ and Martin Hepp http://www.heppnetz.de/projects/goodrelations/, was an oddity in this wonderful article.
Hi Christopher. Glad you like the article, thanks! And yes, there’s even more to it and if you’d like to be strict, you also need to go back even before the dawn of the web ;)