Preventing your site from being indexed, the right way

We’ve said it way back when, but we’ll repeat it: it keeps amazing us that there are still people using just a robots.txt files to prevent indexing of their site in Google or Bing. As a result, their site shows up in the search engines anyway. Do you know why it keeps amazing us? Because robots.txt doesn’t actually do the latter, even though it does prevent indexing of your site. Let me explain how this works in this post.
For more on robots.txt, please read robots.txt: the ultimate guide. Or, find the best practices for handling robots.txt in WordPress.
There is a difference between being indexed and being listed in Google
Before we explain things any further, we need to go over some terms here first:
- Indexed / Indexing
The process of downloading a site or a page’s content to the server of the search engine, thereby adding it to its “index.” - Ranking / Listing / Showing
Showing a site in the search result pages (aka SERPs).
Read more: What is indexing in regards to Google? »
So, while the most common process goes from Indexing to Listing, a site doesn’t have to be indexed to be listed. If a link points to a page, domain, or wherever, Google follows that link. If the robots.txt on that domain prevents indexing of that page by a search engine, it’ll still show the URL in the results if it can gather from other variables that it might be worth looking at.
In the old days, that could have been DMOZ or the Yahoo directory, but I can imagine Google using, for instance, your My Business details these days or the old data from these projects. More sites summarize your website, right.
Now if the explanation above doesn’t make sense, have a look at this video explanation by ex-Googler Matt Cutts from 2009:
If you have reasons to prevent your website’s indexing, adding that request to the specific page you want to block like Matt is talking about, is still the right way to go.
But you’ll need to inform Google about that meta robots tag. So, if you want to hide pages from the search engines effectively, you need them to index those pages. Even though that might seem contradictory. There are two ways of doing that.
Prevent listing of your page by adding a meta robots tag
The first option to prevent the listing of your page is by using robots meta tags. We’ve got an ultimate guide on robots meta tags which is more extensive, but it basically comes down to adding this tag to your page:
<meta name="robots" content="noindex,nofollow">
If you use Yoast SEO, this is super easy! No need to add the code yourself. Learn how to add a noindex tag with Yoast SEO here.
The issue with a tag like that though, is that you have to add it to each and every page.
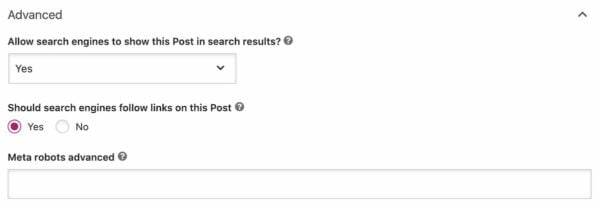
Or by adding a X-Robots-Tag HTTP header
To make the process of adding the meta robots tag to every single page of your site a bit easier, the search engines came up with the X-Robots-Tag HTTP header. This allows you to specify an HTTP header called X-Robots-Tag and set the value as you would the meta robots tags value. The cool thing about this is that you can do it for an entire site. If your site is running on Apache, and mod_headers is enabled (it usually is), you could add the following single line to your .htaccess file:
Header set X-Robots-Tag "noindex, nofollow"
And this would have the effect that that entire site can be indexed. But would never be shown in the search results.
So, get rid of that robots.txt file with Disallow: / in it. Use the X-Robots-Tag or that meta robots tag instead!
Keep reading: The ultimate guide to the meta robots tag »

Hi there
I feel I have various issues (no idea though?) with my site and I am paying someone for 3 hours per month to sort the SEO . But I do not know what exactly he does, but I feel that nothing has improved in the last 2 years. Someone said to me to add SEO keywords into my product info, which is probably a good idea, but I have no idea what to do for the better?
I am looking for something that does the SEO and updates and all else that a good site needs ‘automatically’. Is that possible or am I asking for to much??
Hi Viola! I’m afraid I can’t really advise you on whether hiring someone can help with your rankings, but I can tell you what our plugin can help you with! Yoast SEO Premium does make sure that your technical SEO is in order. In addition, it gives you feedback on your writing to help you write readable and SEO-optimized content. That being said, it doesn’t write your texts for you so that does mean that you (or someone you hire) still needs to put in the effort to get your pages ranking. SEO does require some real love and attention :)
We do have a lot of posts on our SEO blog that can help you with SEO, copywriting and other related topics. Plus, we offer training courses that can help you master SEO yourself. So, to answer your question: our Yoast SEO Premium plugin can definitely make your life easier and help you with your SEO, but unfortunately SEO isn’t something you can automate. I hope this explanation helps you!
Thank you for sharing this info. Pls i don’t know why my post are not showing up on search engine even if i type the Title of my Post is steel can’t find it on the search result.
Hi there! Sorry to hear about that, I think this article on why doesn’t Google index my content properly? can help you figure out what’s going on :) Good luck!
Thanks for the info. Anyway I will continue to keep the .txt file and Yoast SEO in unison.
You’re welcome, Mel!
This SEO and Yoast leaves me confused. I send a lot of letters to the editor and had a newspaper column for a time. I got numerous accolades for my writing as I did when deployed . Accord to Yoast I suck. Every thing I write is low scored. To me it seem the SEO/Yoast demands self censorship. So now I ignore SEO/Yoast and write as I choose.
Hi there, Melvin. Thanks for your comment! We definitely do not want to give you the idea that you need to censor your writing. To give you some more context, we have written a few blogs that explain how our analysis works. But that being said, of course, it’s always up to you whether you want to do something with the feedback that is given :) it is just meant to help you find points of improvement and write a more readable text.
– https://yoast.com/yoast-seo-readability-analysis/
– https://yoast.com/yoast-seo-hates-my-writing-style/
I click on the “Discourage search engines” button and it adds the same robot meta tag. Later I have to remove it manually
Hi, Derek! This “Discourage search engines” button sets your entire site on noindex,nofollow. With Yoast SEO you can be a lot more nuanced and choose which parts of your site you want to noindex and which parts you do want to have indexed. It allows you a lot more freedom when it comes to preventing specific parts of your site from being indexed.
Thank u for sharing this information . I hope this will work for me for sure.
You’re welcome and good luck!
Hi yoast i am new in SEO filed can i ask how to index my website on google?
Hi there, Sana! We have an article on SEO that discusses all the basics! This will help you check whether you’ve set everything up right :) https://yoast.com/wordpress-seo/
Let me know if you have any other questions!
Great info although !! what to do if we do not want our page in search results like privacy page,disclaimer or order process
You’re welcome! Glad it’s helpful :)
Thanks for sharing
You’re welcome!