Optimizing internal search in WordPress

WordPress comes with a basic internal search system, but it has lots of room for improvement. If your webpage has more than just a few pages, you should definitely make sure that you’re providing a great internal search experience. Read on to understand why!
Search is how we… search
In the early days of the internet, users navigated the web by clicking through lists and directories of links. However, as search engines became more popular, that behavior changed. Now, Google (and others) have normalized search as the way in which we explore the web. Instead of just hopping from link to link, we describe what we want, and get a list of options.
Chances are, your users have the same expectations of your website. Many of the people who arrive at your website will have a specific question in mind. Or maybe they’re looking for a specific piece of information. If they don’t immediately see what they’re looking for, then they’ll likely expect to be able to search. After all, that’s much easier than having to learn how your website is structured and browsing through your lists of links.
If there’s no option to search, a confused or lost user might simply leave your website. And if that happens a lot, it might create the kinds of negative user experience signals which may lead Google to think that your pages aren’t good results. But if you provide a great search experience, that might create positive user experience signals, which may benefit your SEO.
WordPress’ internal search is okay
The good news is that WordPress supports internal search “out of the box”. Many themes come with a search box in the header, sidebar or footer. Users can type in a keyword or phrase, and WordPress will send them to a page that lists the top content on the site which matches that search.
But the results aren’t always great. It’s not always clear what you’re looking at. It can be hard to sort, filter, and find the right result. And it’s not always clear how to even search in the first place.
If you’re using the default WordPress’ search feature, there’s a lot that you can do to avoid these problems and to provide a great user experience.
Optimizing your internal search experience
Your internal search system is typically split into three parts. There’s a form where users input their query, the page that displays the results, and the underlying system which delivers those results. There are a lot of ways in which you can assess and improve each of these, in order to provide a great user experience.
The search form
The search form is where your users start their search. But only if they can find or recognize it! To make sure that people use your search system, you should make sure that:
- It’s easy to find. People might overlook search features in menus, footers, or other ‘hidden’ areas.
- It’s obvious and recognizable. Input fields should look like input fields, so use a search icon, and say ‘search’ in the placeholder.
- It behaves conventionally. Fancy features which change how the input field looks, works or behaves might confuse or challenge users. Customizations and enhancements shouldn’t break the basics.
- It has a ‘search button‘. Hitting ‘enter’ should submit the form, but users who don’t know that should be able to click a helpfully labelled ‘submit’ button instead.
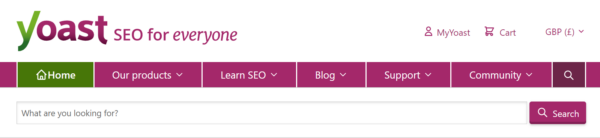
The search results page
Once users have typed and submitted their search query, they’ll expect a set of results. Those should help them to quickly identify the best answer to their question (or to try again with a new search term). To streamline that as much as possible, you should make sure that:
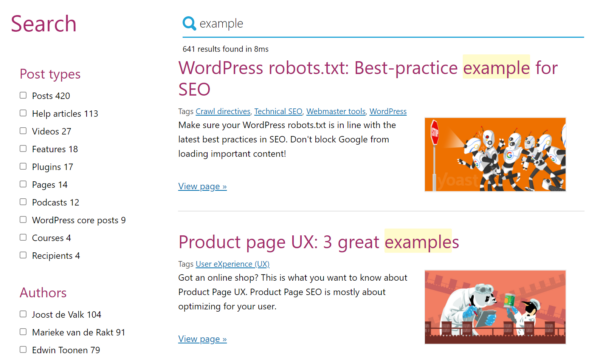
- Results are ranked by relevancy. Older versions of WordPress used to order results by date, so make sure you’re up to date!
- Results contain relevant snippets. Seeing the title, (revelant) excerpt, and potentially even the thumbnail image of each result helps users to narrow down the list.
- The search keyword is highlighted. Showing the term the user searched for in the context of each result makes it easier to understand the context and content of each result.
- The right types of content are shown. Users on an ecommerce store probably don’t want to see your blog posts in your search results. You probably also don’t want to include private, unpublished, or otherwise non-public content. Managing which content types are included (or allowing users to filter the results) is key to delivering a good result.
- There’s useful metadata and tools. Showing the number of results and providing pagination can help the user identify when a search might have been too generic.
- It’s easy to search again. Including a search form in the content or template area, perhaps in addition to the one in the header or sidebar, makes it easy to refine and search again.
- There’s a good ‘no results’ experience. Empty results pages should help the user to understand the situation, make suggestions, provide helpful links, and guide them to a successful outcome.
- It’s all noindexed, or blocked entirely. It’s best practice to keep your internal search results pages out of Google and other search engines (Yoast SEO handles this automatically for you)!
Block your site’s search result pages
Let’s dive a little deeper into the last tip: “It’s all noindexed, or blocked entirely“. Why is it better to prevent your internal search results pages from being shown in Google?
Most importantly, sending a user from a set of search results to a set of search results is a poor experience. People searching on Google want answers, products, information and a destination. If they have to search again or browse through a second set of search results, then they’re unlikely to have a good experience.
From a technical perspective, it’s good practice to help Google avoid crawling and indexing ‘infinite spaces’ like search results. You usually won’t want search engines to be spending resources exploring these types of URLs, at the expense of them spending time and energy on your more important content.
There are two ways options for managing how internal search URLs are crawled and indexed:
- You can allow search engines to crawl internal search results pages, but prevent them from indexing them by using a meta robots tag with a value of
noindex, follow. Yoast SEO sets this for you automatically by default. This approach allows them to discover content linked to from these pages, but might mean they get lost or waste resources exploring. - You can prevent search engines from crawling by using a robots.txt disallow rule. This will guarantee that search engines don’t visit (or get lost in) your search results page, but it might cause some side effects. Notably, search engines won’t be able to discover pages linked from internal search results pages, and results pages might still get indexed. Yoast SEO Premium’s crawl cleanup settings allow you to configure this behaviour, or, you can manually edit your robots.txt file.
The underlying system
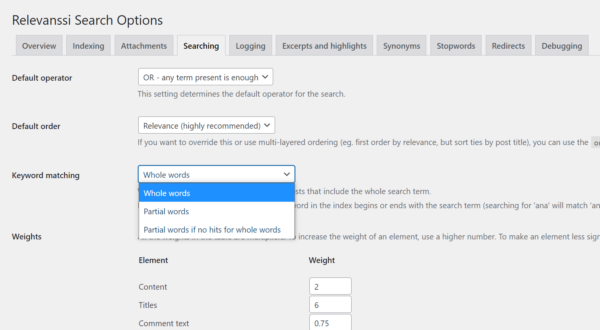
Many WordPress websites rely on the ‘native’ search functionality which comes built into the software. However, there are several third-party systems and plugins which can radically improve the quality of your results.
We’re big fans of the SearchWP and Relevanssi WordPress plugins; both of which do a great job of allowing fine-grained customization (such as handling plurals and stemmed words), as well as searching all sorts of content formats; from product attributes to custom fields, to text in PDF files. Both plugins provide lots of tools, tricks and settings to help you ensure that your users find what they’re looking for.
But there’s still a problem. Both of these platforms are still limited by operating within WordPress’ confines; which can limit their performance, flexibility, and capabilities. If you’d like to unlock even more firepower and customizations, then we recommend using a ‘hosted solution’ – which means that the data and search process happens on their servers, not yours.
We’re big fans of Algolia; they’re one of the leading players in the market when it comes to hosted search solutions. Unfortunately, they discontinued their official WordPress plugin; however, the team at WebDevStudios is maintaining a new version. We’re particularly keen on this approach because it integrates cleverly with the Algolia feature in Yoast SEO.
With some very minor tinkering, you can use Yoast SEO’s internal linking data (which records which of your posts link to each other) as a ‘weight’ in your search logic. That means that your most linked-to content is more likely to rank highly in your internal search results. That means that users are more likely to find your best content.
You can read more about how to configure that integration here.
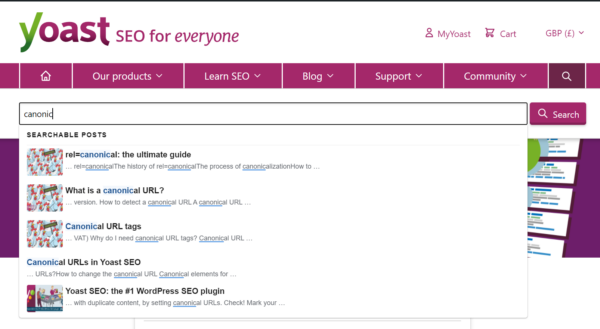
Many of the more sophisticated search systems (including Algolia) also offer ‘live search’ capabilities. These return results as the user types into the search box. That might help users to find what they’re looking for without even needing to submit their search. It may even completely remove the need for them to visit the search results page.
Extra tips
Use internal search analytics to improve your website
Not only is providing a robust, feature-rich internal search system helpful for your users – it can also help you to improve your website and your content.
Tracking systems (like Google Analytics, and some plugins’ own monitoring systems) can record how visitors use the search system. Data on what people search for, and whether it looks like they find what they’re looking for, can be invaluable when optimizing your site. This article on Moz has some great tips on where to start, with nothing more than a basic setup and Google Analytics. More sophisticated setups, like Algolia, can provide much more sophisticated analysis and deeper insight.
Identifying bad experiences – like searches with no results, or where people don’t find what they’re looking for – is the first step to fixing them. That might mean improving content, writing new content and pages, or just doing some digital housekeeping!
Expose your internal search in Google
You may have seen that sometimes, Google may show a search input field within the search results for a site. When a user searches from that field, Google sends them directly to the search results page on that site.
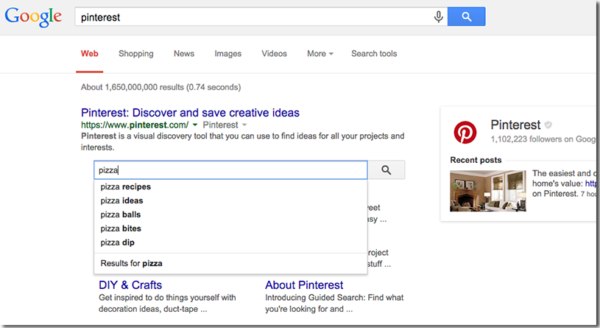
This is typically powered by structured data, which Yoast SEO automatically outputs on your site. Google won’t always show this (and will rarely show it at all on small or simple websites) but may choose to if it thinks that it’ll help users to navigate larger or more complex sites.
Note that you can opt-out of this by adding the following meta tag to all of your pages:
<meta name="google" content="nositelinkssearchbox" />Disabling search in WordPress
If we’ve not convinced you that providing a great internal search experience is a good idea, then don’t worry. It’s possible to disable the internal search functionality on your WordPress website.
At least, sort of. There’s not actually a native way to simply ‘turn off’ search on a WordPress site. In fact, many websites simply remove (or never build) a search bar, without realizing that anybody appending ?s=search-term to their website will be sent to a search results page. What’s worse is, these templates and pages are rarely styled (or built/defined at all). That means, when you view them, they often seem broken and confusing.
If you don’t want users to be able to search on your site, you’ll need to tinker with your theme logic to remove the dead-ends. Alternatively, you can use a plugin like this one.
Businesses win more customers by getting them found the first page on Google search. If one is not on the first page, chances are he/she is losing customers to competition just because of not implementing an effective SEO strategy. SEO is an ongoing process and needs constant monitoring and adjustments of your website.
Awesome content. Thanks!
Thanks, we’re glad you liked it!