The feature that almost made it

This post explains a feature we built, and then removed from Yoast SEO 18.3 just before release. It could have been pretty annoying when we released it, so I’m happy we didn’t but I also wanted to share just how hard this sort of thing is to prevent.
The feature idea
On February 15th, I saw a tweet by my friend and very well respected SEO Jon Henshaw, with an absolutely awesome idea: adding a QR code to the end of a page when it’s printed, so you could easily get back to the online version. Super simple, very clever, I loved it.
I loved it so much, I reached out to Jon and said “would you mind if I added this to Yoast SEO?“, to which Jon responded:
It’s an idea meant for sharing and copying. I’ll take it as flattery :)
You can see why I like Jon.
So I built the feature. I tried to build it such a way that we wouldn’t load the image when the page wasn’t being printed. I didn’t succeed at that at first, but then Herre, our lead architect, helped me and we got to a very nice bit of code that would inject a bit of HTML into the DOM right before printing. That piece of HTML would load a QR code that would be generated at that point (just-in-time), so we weren’t wasting any resources when it wasn’t needed.
Security in mind
In generating that QR code, we needed to consider the security aspect: we couldn’t create a QR code generator that would allow rendering QR codes for all the web. So we added a nonce, and verified that nonce before generating. Since the nonce was time-based too, it would stop working after a while. If you’d pass it an invalid nonce or no nonce at all, the code would return a 400 HTTP status code.
All of this combined made us think we’d made a fun little feature, and a quite solid one in fact. So we merged it to our development branch and it went into our Release Candidate.
Test, test, then test some more
If there’s one thing we’ve learned at Yoast over time it’s that testing is paramount. Our QA team is, I dare say, one of the best in the WordPress ecosystem. We test every Release Candidate (RC) for two weeks. In all sorts of scenarios, we also deploy this RC to yoast.com to catch errors there.
The point with testing is: you need to know what you’re looking for. And this feature was working very nicely. It worked as expected, everything was going fine. Ready for release. Until I checked our GSC error report on the morning of the 18.3 release and saw this:
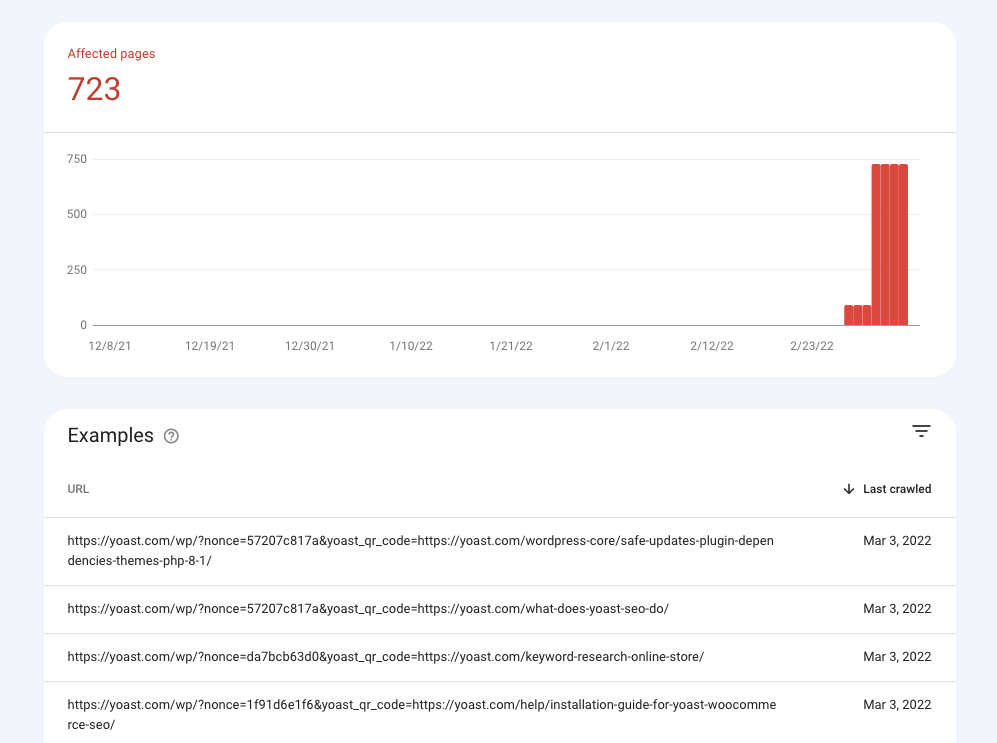
Why is Google crawling these? Why is it giving errors?
So, first of all, I thought: why is Google crawling this? These URLs aren’t in the normal DOM, there are only two ways Google could have found these: either it’s crawling all URLs it finds on a page or it’s pretending to be “printing” every page. The latter seems a bit far-fetched, so I think we can safely assume that Google is crawling every URL it finds, even if it’s inside a piece of JavaScript. I think that’s… Ugly. But it’s not something I can prevent them from doing.
The output looked something like this (minified, of course):
<script id="yoast_seo_print_qrcode_script">
window.addEventListener( "beforeprint", function() {
var div = document.createElement( "div" );
div.innerHTML = "<img src=\"https://yoast.com/wp/?code=672db5ff9692498bc61bbcfbc5aed95f&yoast_qr_code=https%3A%2F%2Fyoast.com%2F\" width=\"150\" height=\"150\" alt=\"QR Code for current page's URL.\" /><p>Scan the QR code or go to the URL below to read this article online.<br/>https://yoast.com/</p>";
div.style = "text-align:center;";
div.id = "yoast_seo_print_qrcode";
var script = document.getElementById( "yoast_seo_print_qrcode_script" );
script.parentNode.insertBefore( div, script );
} );
window.addEventListener( "afterprint", function() {
document.getElementById( "yoast_seo_print_qrcode" ).remove();
} );
</script>So Google was grabbing the URL from that img tag inside the JavaScript. That’s going quite far if you ask me.
The second question is: why is this giving errors? Because if you crawled this, those URLs would work. Except that these nonces are time-based, so if you’d crawl them again a couple of days later, they would stop working. And it turns out, from our bot logs, that that’s exactly what happened!
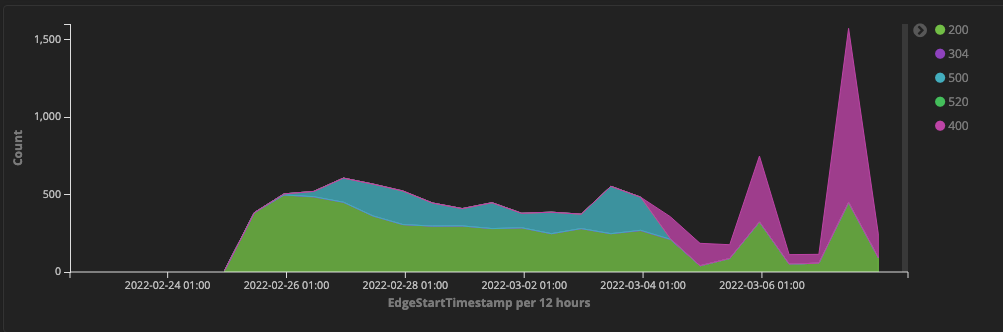
When I saw this I was super glad we built it like this, because we’d never have seen the error if we hadn’t built it this securely. And not seeing the error would mean we probably hadn’t seen that this adds a ton of crawling for every site it’s added to.
So we’re adding a new layer of reports to look at before we release a feature like this, to see if it’s changing crawl behavior. Unfortunately, with all the new APIs Google is launching for Google Search Console, we still haven’t gotten an API that actually gives us all the errors for a site. That’s an API that used to exist but no longer does, and we need that back badly. Google Search Console also doesn’t email you when you suddenly have hundreds of new errors on your site. Which to me is weird because it will email you when you have one typo in your Schema somewhere.
Conclusion
Of course, when we saw all this, we took the feature out of our Release Candidate. It’s the only logical conclusion: this will add more unnecessary things for Google to crawl, which is the opposite of what we try to reach with Yoast SEO. We’ll try to come up with a better approach to this feature, but it’s not worth causing extra crawls, which has a very real energy usage and thus environmental impact, so unless we find a reliable way to prevent that, it won’t make it.
When evaluating new features, you already needed to take a ton of things in mind: is it fun? Will it add something meaningful? Will it be worth it to maintain it over time? Does it add potential security vectors? We can now add another question to that list: will search engines crawl the output in weird ways and will that cause issues?
Joost is an internet entrepreneur and the founder of Yoast. He has a long history in WordPress and digital marketing. On our blog, he has written a lot about SEO in general, technical SEO and important topics related to SEO.

Introduction to Yoast SEO webinar
A practical, demo-driven webinar on using Yoast SEO for WordPress with confidence.
All Yoast SEO WebinarsWordCamp US 2026
Team Yoast is Attending, Sponsoring, Yoast Booth at WordCamp US 2026! Click through to see who will be there, what we will do, and more!
See where you can find us nextThe SEO Update by Yoast – August 2026
Expert analysis of the latest SEO & AI news developments with Carolyn Shelby and Alex Moss. Watch the update here. 📺
All Yoast SEO Podcasts
Thank you for sharing! I was not expecting Google to crawl URLs. Do you think it would’ve crawled it if it was relative path only?
Also, can you share what solution you are using for bot logs?