Why Schema needs to be a graph

More and more people, and more and more developers, are talking about structured data, and Schema.org. We talk and have talked about Schema for quite some time at Yoast and we’ve built loads of things with and on top of it. Recently, the proposed block protocol standard started talking about integrating with Schema, and WordPress’ core team is also taking an interest; see this discussion on Github.
Schema.org metadata is a machine-readable and interpretable version of what’s on a page. We at Yoast are very proud of the schema markup Yoast SEO generates. The main reason we’re so proud of it is that we go to great lengths to ensure that when a machine reads it, it interprets it correctly. To do so, we have determined that Schema should always be one inter-connected graph.
What a good graph looks like
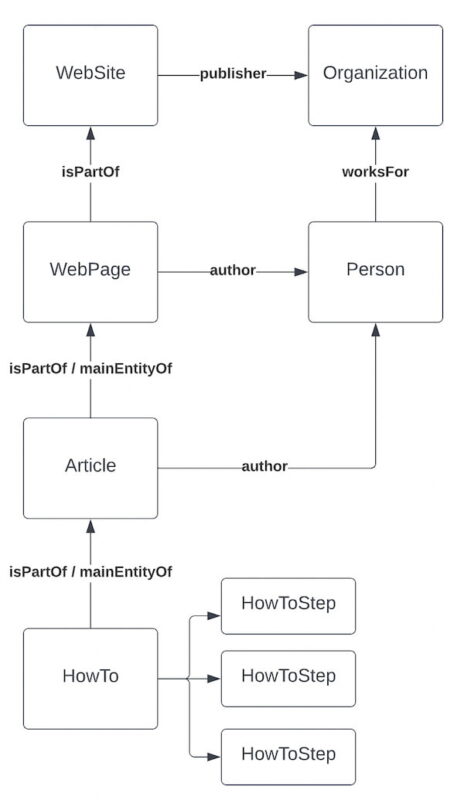
Let’s say we have a page with an article, and that article contains a HowTo. We’ll assume that the HowTo is the “raison d’être” of the article. Our Yoast SEO graph, when parsed, would look like this:
HowTo- Part of
Article- Part of
WebPage- Part of
Website
- Part of
- Part of
- Part of
The Article and WebPage would have one or multiple authors, publishing dates, images, the website would be owned by an organization, etc. There is a ton of metadata in our Schema, which is super helpful to search engines. Some of the data is page level (like language), some of the data is usually site level (like publisher), and this all works out fine because we tie it all together.
In many Schema implementations, these parts are not tied together as a graph. They are thrown out as separate blocks. So instead of the nice hierarchy above, you’d get:
HowToArticleWebPageWebSite
And in the case above, that might actually be fine. I say might for a reason. What if the HowTo is actually only a tangential part of the Article? There are cases where it becomes even more critical. Let me give you an example.
When Schema becomes destructive
This is, unfortunately, a case I encountered in real life. A website had a product page for a single product. Below that product, it listed five related products, things commonly bought together, etc. The component used to show those related products’ output Schema for those five products. It didn’t tie into the rest of the page’s schema. So you got this:
Product(main product)WebPageWebSite
Product(related product 1)Product(related product 2)Product(related product 3)Product(related product 4)Product(related product 5)
Product schema is responsible for getting a site the nice rich snippets that show star ratings, price, and availability of products in the search results. In this case, search engines didn’t know which product to pick; in fact, Google’s rich result testing tool won’t even give you a result. When you look at this schema out of the context of its design, there’s no way to know which product is the main product on the page because the Schema wasn’t tied together into a single graph. The result is a loss of rich snippets for these pages. A change that was directly attributable to a loss of sales.
Fixing it meant connecting the five related products to the main product with isRelatedTo properties, removing the Product part of their output, and then declaring the main product as the mainEntityOfPage. The point here is that those product blocks needed to behave differently based on context and their relationships to other blocks on (and information about) the page. This is the sort of understanding that you need to be able to build working Schema output.
The geeky bits: how we tie it all together
In our graph, we tie all elements together by specifying their relationship. To do so, we reference graph “pieces” as we call them, by @id. A WebPage has an attribute isPartOf, referencing the WebSite piece. An Article has an isPartOf referencing the WebPage. In fact, an Article by default also has an attribute mainEntityOfPage that references the WebPage, declaring itself as the main entity.
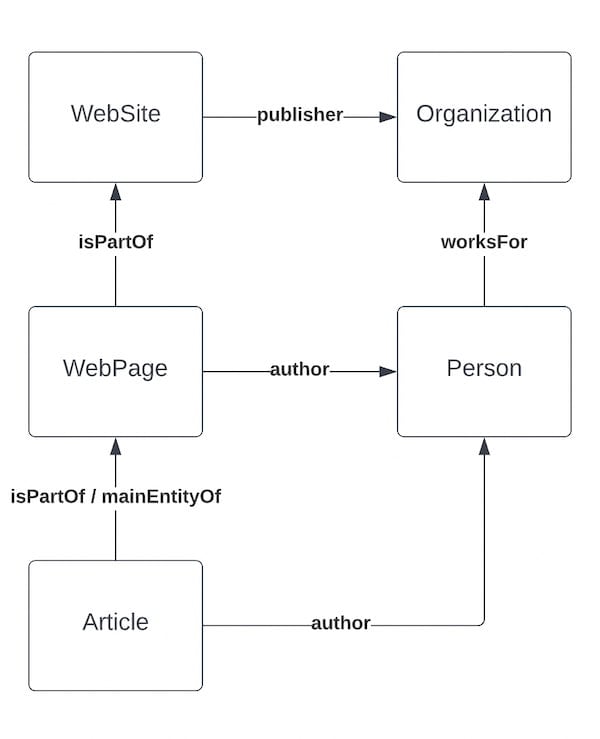
If you add a HowTo to that mix, it would declare itself the mainEntityOfPage of the Article. If the HowTo is part of a page that doesn’t output Article schema, it would do the same but automatically attach itself as the mainEntityOfPage of the WebPage. This way, a search engine can parse the graph and see exactly what is going on. That means that each block needs to be aware of its context when its schema is rendered.
So: Blocks and Schema are not one and the same
While blocks in the new WordPress editor are great for use with Schema, they require an extra level of parsing and a layer of business logic to be tied to the rest of the page. Unfortunately, it’s not as simple as just outputting schema for each block and leaving it at that. The idea currently being discussed on the WordPress core GitHub, to tie Schema to Patterns, is, in my opinion, a bit too… Simplistic. I’m not saying it can’t be done, but it needs more work. The same is true for discussions around the Block Protocol.
If you want to implement Schema, you have to be willing and able to determine the whole context of a page. That business logic is complex, interconnected, and continually evolving as Google, and other consumers alter and evolve their standards. This logic cannot live in each individual block, in individual pieces; it needs a “brain” that understands all the moving parts and can describe a cohesive graph of all those moving parts.
We take great pride in what Yoast SEO does in that area, and we offer a Schema API that allows other developers to tie into that and add their own implementations. We have also written a full Schema specification of just how our output works and why. Without this “brain”, a block-based approach will struggle to meaningfully and safely describe a page.

This is really great. i think i will switch from seopress to yoast this time around just to benefit from the schema – though yaost is a little bit more expensive