RSS feeds in the age of Panda and Penguin

When I started blogging, everyone used an RSS reader and your RSS feed was the way of getting your new content in front of people. The use of RSS has dwindled, at least for us because the readership here on Yoast has quadrupled over the last 2 years but the number of RSS subscribers is now less than 1/4th of what it was 2 years ago, let alone the traffic.
This post contains outdated advice, but we’ve kept it online for posterity.
We had a passionate discussion about full-length RSS versus summaries in those days. Full length would mean people could read your content but would not get to your website, meaning you’d have fewer ad views if that was how you made money. On the other hand, especially tech-savvy people preferred full-length RSS because it was easier to read. In fact, I think a lot of people who still use RSS still do prefer full-length RSS. There are just so few left.
A decline in usage of RSS
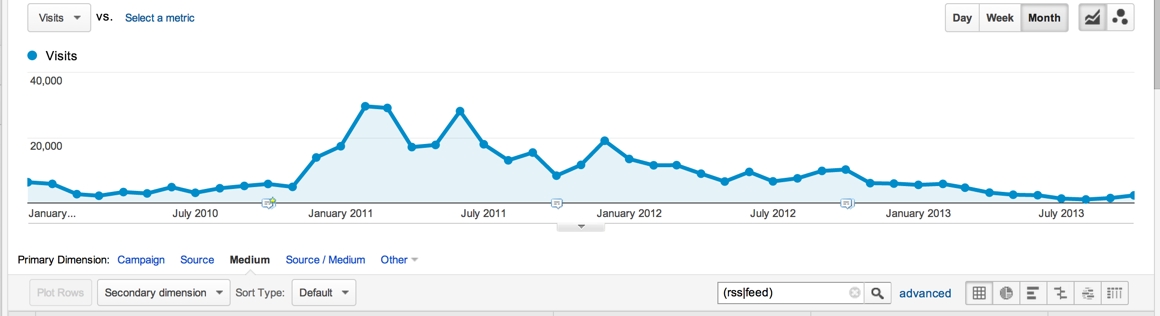
Using our Google Analytics plugin we’ve been tracking RSS click-throughs to our site for several years now and that statistic tells a tale of steady decline slowly going to zero: FeedBurner, which I used to love with a passion died quickly when it was bought by Google and in the last few days I’ve actually, finally, made the move off of FeedBurner to FeedPress, which is a rock-solid replacement. It shows us as having around 12,000 RSS subscribers. If you consider we had just 2,340 clicks from RSS last month (which is less than 0,5% of our traffic), you could argue that 12,000 RSS subscribers don’t necessarily help us much, but we honestly also don’t really know because we don’t know who read our posts. So RSS is becoming less important, at least to us. At the same time, RSS is not without its dangers from an SEO perspective.
RSS and SEO
Scraper sites have been feeding (pun intended) off of RSS feeds for years, pulling in all the content and republishing it in the hope of ranking in the search engines with that content. This lead to duplicate content problems in the search results which had to be mitigated, or a scraper site with a bit more authority than your simple blog would simply outrank you with your own content.
From the very beginning, our Yoast SEO plugin has, for that reason, had the functionality to add links back to your site at either the bottom or the top of those RSS feed articles. This practice, which we first invented in January 2008 in our RSS footer plugin, worked like a charm for quite a while. It showed search engines the original source of the article and while a large portion of these scrapers removed all links, the few that let the links go in actually helped in getting Google especially to float the right content to the top.
We actually used that functionality ourselves to add some more links to specific pages on yoast.com to help those pages rank. Now over the last few years, while checking the rankings of those pages for the specific keywords we were targeting, we saw a trend of steady decline in rankings. This is almost certainly the result of Google treating too many exact anchor texts as negative.
Along came the Panda
When Google released its Panda update/filter, that hit a lot of scraper sites and the duplicate content ranking problems began to be somewhat less of a problem.
If a truly high authority site copies your content and doesn’t link back you’re still done for, as you stand no chance of ranking. “Silly” scraper sites had a bit more of a hard time ranking. But linking back the way we used to was still a better solution than doing nothing in our experience. Overall, I was rather happy with Panda, it seemed the first time in a couple of years where Google had really made a difference.
But then… Penguin hit.
Among our site review customers, we’ve historically had a fair portion of Penguin victims. Google’s Penguin update should be hitting sites that have lots of low-quality links pointing at them. You can probably guess how this is a problem… The sites that had used to help us rank our own articles a couple of years before, were now dragging us down.
To be honest, I’ve not seen a site that was hit by Penguin purely based on these RSS scraper links. Usually, there were large portions of other, problematic, usually obviously paid for, links. More recently though, we’ve seen more and more people who needed to do link removals and / or disavow for sites that had links because of scraping their RSS feeds. So what was once a best practice is now a bad practice.
As a result, we’re slightly changing how the functionality in WordPress SEO works as of the next version. If you’ve had it configured to link back to you, you don’t need to do anything if you don’t want to, the only change is that those links will be nofollowed from now on, so Google doesn’t count them. We’ve added a filter nofollow_rss_links that defaults to true. If you return false on that filter the nofollow will be removed but there will be no option to do so in the settings area for the plugin as I think it’s a bad idea.
Taking it to the extreme
Some SEO’s, like Dave Naylor, have taken it to the extreme, they’ve removed all content from their RSS feeds outside of their titles or even removed the RSS feeds altogether. Doing the former is actually not that hard in WordPress either:
/**
* Removes the content from the RSS feed and replaces it with a custom message.
*
* @param string $content
*
* @return string
*/
function yst_clean_rss( $content ) {
if ( is_feed() )
return 'This is a new post on yoast.com, Whoopity Doo!';
return $content;
}
add_filter( 'the_content_feed', 'yst_clean_rss', 90, 1 );
add_filter( 'the_excerpt_rss', 'yst_clean_rss', 90, 1 );I’m not 100% sold yet on whether that approach is a good idea for everyone, but in our good old tradition of eating our own dog food, we’re going to try it here on Yoast first to see what happens. It might be good to note that we’ve already had our first complaints from readers. I’m curious what you all think and what you think about RSS in the first place!
Update: after feedback from some very valued readers from the WordPress community, I’ve decided to put our full feeds back on. I first DMCA’d some 40 odd sites and had them remove our content though. We’ll be sure to keep a closer eye on where our content is going henceforth, as it was rather shocking to see just how many full feed scrapers were out there…
